Azure AI Vision - Anwendungen mit AI-basierter Bild-Analyse ausstatten
Azure AI Vision revolutioniert deine Bildverarbeitung: Automatisiere Analysen und steigere Effizienz mit KI.

Azure AI Vision - Einführung in die programmatische Azure KI Bildanalyse
Ein interessantes Beispiel für die Vielfältigkeit der Azure-AI-Dienste ist der Image-Analyse-Dienst Azure AI Vision. Ich habe dir bereits gezeigt, wie du die einzelnen Features und Fähigkeiten des Vision-Dienstes im Azure AI Vision Studio ausprobieren kannst. In diesem Beitrag geht es nun darum, diese Fähigkeiten exemplarisch mit Hilfe des SDKs für .Net in deinen eigenen Programmcode einzubetten. Mehr dazu lernst du im Kurs AI 102.
Azure AI Vision ist ein Azure-Dienst, mit dessen Hilfe Softwaresysteme visuelle Eingaben durch Analyse von Bildern interpretieren können. Der Azure AI-Dienst bietet vorgefertigte Modelle für gängige Computer-Vision-Aufgaben, einschließlich der Analyse von Bildern, um Bildunterschriften und Tags vorzuschlagen, und der Erkennung gängiger Objekte und Personen. Du kannst den Azure AI Vision-Dienst auch verwenden, um zum Beispiel den Hintergrund eines Bildes zu entfernen (Freistellen).
Umgebung vorbereiten
Lass uns gleich starten, den Dienst im Kontext einer eigenen Anwendung auszuprobieren. Wie immer, möchten wir hierbei keinen eigenen Code entwickeln, sondern evaluieren, wie du von Microsoft bereitgestellte Beispielanwendung in der Umgebung deiner Wahl mit Hilfe der Analyze-Image-API ausprobieren kannst. Die Code-Beispiele, auf denen dieser Beitrag basiert, stellt Microsoft auf diesem https://github.com/MicrosoftLearning/mslearn-ai-vision Git Hub -Repository zur Verfügung. Ich verwende für diesen Beitrag VS Code als Entwicklungsumgebung und binde dieses Repo zunächst in VS Code ein. Dazu gibt es zahlreiche Möglichkeiten. Du kannst das Repo z. B. vorher in dein lokales Arbeitsverzeichnis klonen (git clone https://github.com/MicrosoftLearning/mslearn-ai-vision.git) oder du lädst das Repo als Zip-Archiv herunter und entpackst es. In beiden Fällen kannst du diesen Ordner in VS Code öffnen. Du kannst das Repo auch direkt aus VS Code klonen. Suche dazu in der Befehlpalette (F1) nach „Git:Clon“:
 Klonen eines GitHub-Repository aus direkt aus dem VS Code
Klonen eines GitHub-Repository aus direkt aus dem VS Code
Azure-AI-Vision-Ressource
Als nächstes brauchst du eine neue Azure-AI-Vision-Ressource. Diese legst du wie bereits in diesem Artikel (AI-Vision-Studio-Artikel) im Azure-Portal an. Suche dazu nach „Azure Ai services“ und erstelle wahlweise eine Ressource vom Typ „Maschinelles Sehen“ (Computer vision) oder „Azure AI services multi-service account“. Ich verwende für dieses Beispiel letzteren Ressource-Typ.
Aber Achtung: Dieser Ressource-Typ (Azure AI Vision 4.0) ist im vollen Funktionsumfang derzeit nur in den Regionen East US, West US, France Central, Korea Central, North Europe, Southeast Asia, West Europe oder East Asia erhältlich.
 Erstellen einer Azure-AI-Vision-Ressource
Erstellen einer Azure-AI-Vision-Ressource
Sobald der Ressource-Typ erstellt wurde, kannst du dich um die Bereitstellung des Azure AI Vision-SDKs kümmern. Öffne dazu im VS Code den Order „…Labfiles/01-analyze-images/C-Sharp/image-analysis“ im integrierten Terminal. Das geht am schnellsten, wenn du den Ordner im VS-Code-Explorer markierst und dann im Kontextmenü den Eintrag „Im integrierten Terminal öffnen“ auswählst. Bei dem bei mir gewählten lokalen Arbeitsverzeichnis sieht der Pfad aus wie in folgender Abbildung:
 Die notwendigen Vorbereitungen in VS Code
Die notwendigen Vorbereitungen in VS Code
Jetzt kannst du in deinem Terminal das Azure AI Vision SDK installieren. Unter C# klappt das mit …
dotnet add package Azure.AI.Vision.ImageAnalysis -v 1.0.0-beta.3 Installieren der erforderlichen Client-Bibliotheken
Installieren der erforderlichen Client-Bibliotheken
Danach öffnest du die Datei „appsettings.json“ und ergänzt die Werte für „AIServicesEndpoint“ und "AIServicesKey“. Diese findest du in der zugehörigen Azure-AI-Ressource im Menü „Schlüssel und Endpunkt“. Vergiss nicht das Speichern der Datei.
 Anpassen der appsettings.json-Datei zur Authentifizierung des Clients
Anpassen der appsettings.json-Datei zur Authentifizierung des Clients
Nun öffnest du die mitgelieferte .Net-Programmdatei „Program.cs“ in VS Code. Hier importierst du zunächst den Namespace „Azure.AI.Vision.ImageAnalysis“. Ergänze dazu hinter dem Kommentar „// Import namespaces“ folgendes Code-Fragment und speichere die Änderung:
// Import namespaces
using Azure.AI.Vision.ImageAnalysis;Schaue dir die Programmdatei für deine Client-Applikation näher an. In der Funktion „Main“ findest du zunächst den Block „ // Get config settings from AppSettings“. Hier werden AI-Services- Endpunkt und Schlüssel aus deiner Datei „appsettings.json“ eingelesen. Scrolle dann weiter zum Kommentar „// Authenticate Azure AI Vision client“. Hier fehlt noch der Code, mit dem sich dein Azure-AI-Vision-Client-Objekt authentifizieren kann. Füge Folgendes ein
ImageAnalysisClient client = new ImageAnalysisClient(
new Uri(aiSvcEndpoint)
new AzureKeyCredential(aiSvcKey));Ebenfalls in der Funktion „Main“ findest du drei weitere kommentierte Code-Bereiche. Der Code unter „//Get image“ spezifiziert den Pfad zu einer einzulesenden Bild-Datei welche dann an zwei weitere Funktionen „AnalyzeImage“ und „BackgroundForeground“ weiterleitet wird. Du musst hier nicht die im Repository im Unterorder „images“ mitgelieferten Bilder verwenden. Du kannst auch einen beliebigen anderen Pfad, relativ zum Programmverzeichnis angeben. Die zugehörigen Funktionsaufrufe findest du in der Main-Funktion, zu erkennen an den kommentierten Bereichen „ // Analyze image“ und „// Remove the background or generate a foreground matte from the image“. Allerdings sind die zugehörigen Funktionen „AnalyzeImage“ bzw. „BackgroundForeground“ in der Programm-Datei noch nicht implementiert. Das wollen wir jetzt nachholen:
 Die Funktion „Main“ als Startpunkt weiterer Modifikationen
Die Funktion „Main“ als Startpunkt weiterer Modifikationen
Scrolle im Programm-Code herunter zu Funktion „AnalyzeImage“. Dort ergänzt du beim Kommentar „// Get result with specified features to be retrieved“ Folgendes:
// Get result with specified features to be retrieved
ImageAnalysisResult result = client.Analyze(
BinaryData.FromStream(stream),
VisualFeatures.Caption |
VisualFeatures.DenseCaptions |
VisualFeatures.Objects |
VisualFeatures.Tags |
VisualFeatures.People);Außerdem fügst du beim Kommentar „Display analysis results“ diesen Code ein: // Display analysis results
// Get image captions
if (result.Caption.Text != null)
{
Console.WriteLine(" Caption:");
Console.WriteLine($" \"{result.Caption.Text}\", Confidence
{result.Caption.Confidence:0.00}\n");}
// Get image dense captions
Console.WriteLine(" Dense Captions:");
foreach (DenseCaption denseCaption in result.DenseCaptions.Values)
{Console.WriteLine($" Caption: {denseCaption.Text}, Confidence: {denseCaption.Confidence:0.00}");
}// Get image tags// Get objects in the image// Get people in the imageDu kannst nun deine Änderungen sichern und das Programm ausführen:
dotnet run images/street.jpgSchau dir das Ergebnis an. Die Bildanalyse liefert vorerst eine vorgeschlagene Beschriftung (caption) für dein Bild. Vergleiche den Vorschlag mit seinem Bild und teste die KI ggf. mit weiterem Bildmaterial.
 Die Features „caption“- und „Dense Caption“ liefern die aussagekräftigen Bildunterschriften
Die Features „caption“- und „Dense Caption“ liefern die aussagekräftigen Bildunterschriften
Das Feature “image captioning” ist Teil der analyze-image- API. In unserem Fall wird “caption” in den Abfrage-Parameter für „features“ inkludiert. Die Funktion liefert wie üblich eine umfangreiche JSON-Antwort, in der dann der String für „contents“ bei "captionResult" herausgefiltert wird.
result = cv_client.analyze(
image_data=image_data,
visual_features=[
VisualFeatures.CAPTION,Erkennen und Lokalisieren von Objekten
Schauen wir uns nun an, wie die KI in deinem Anwendungscode Objekte in einem Bild erkennen und lokalisieren kann. Bei der Objekterkennung handelt es sich um eine spezifische Form der Computer Vision, bei der einzelne Objekte innerhalb eines Bildes identifiziert und ihre Position durch eine Begrenzungsbox angezeigt werden.
Das Code-Fragment, mit dem du deinen Programm-Code ab dem Kommentar „// Get objects in the image“ ergänzen musst, sieht so aus:
// Get objects in the image
if (result.Objects.Values.Count > 0)
{
Console.WriteLine(" Objects:"); // Prepare image for drawing stream.Close();
System.Drawing.Image image = System.Drawing.Image.FromFile(imageFile);
Graphics graphics = Graphics.FromImage(image);
Pen pen = new Pen(Color.Cyan, 3);
Font font = new Font("Arial", 16);
SolidBrush brush = new SolidBrush(Color.WhiteSmoke);
foreach (DetectedObject detectedObject in result.Objects.Values
{
Console.WriteLine($" \"{detectedObject.Tags[0].Name}\""); // Draw object bounding box var r = detectedObject.BoundingBox;
Rectangle rect = new Rectangle(r.X, r.Y, r.Width, r.Height);
graphics.DrawRectangle(pen, rect);
graphics.DrawString(detectedObject.Tags[0].Name,font,brush,(float)r.X, (float)r.Y);
} // Save annotated imageString output_file = "objects.jpg";
image.Save(output_file);
Console.WriteLine(" Results saved in " + output_file + "\n");
}Speichere erneut deine Änderungen und führe das Programm mit „dot run“ erneut aus, um es mit verschiedenen Bildern zu testen. Die Image-Pfad gibst du wie beim Beispiel oben auch im Programm-Code ca. bei Zeile 30 an:
string imageFile = "images/<your image.jpg";Du kannst erneut die drei im Quellcode-Repo mitgelieferten Beispielbilder im Unterordner „images“ dazu verwenden.
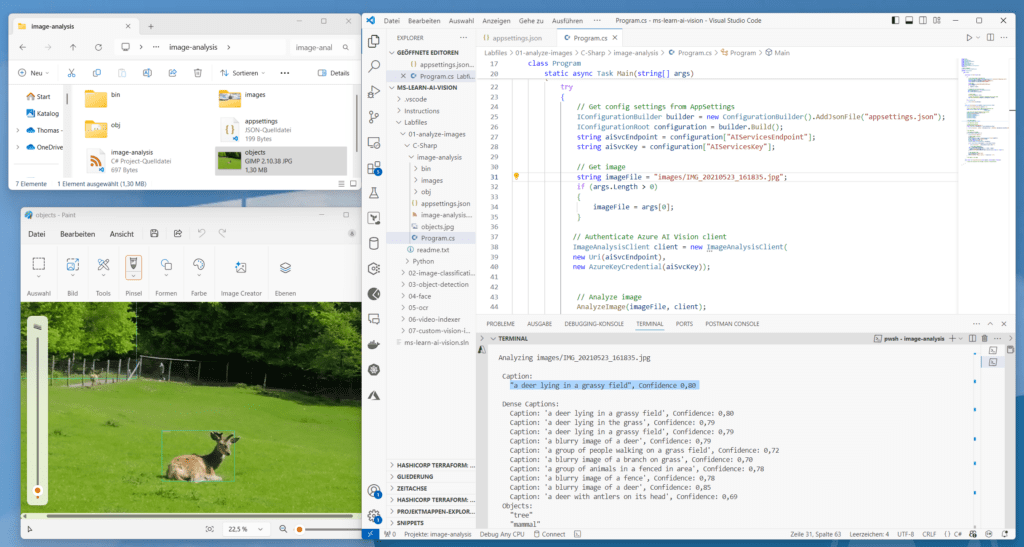 Die Objekterkennung rahmt die erkannten Objekte ein
Die Objekterkennung rahmt die erkannten Objekte ein
Die Objekterkennungsfunktion ist ebenfalls Teil der analyze-image-API.
Du findest in der Programm-Ausgabe diesmal nicht nur einen passenden Vorschlag für die Bildunterschrift, sondern auch eine neue Datei im Programm-Ordner ~\ms-learn-ai-vision\Labfiles\01-analyze-images\C-Sharp\image-analysis mit dem Namen „objects.jpg“, in welcher das Programm die Lage der erkannten Objekte im Bild mit einem grünen Rahmen markiert hat. Teste das Programm unbedingt auch mit mehreren, möglichst unterschiedlichen Bildern.
Die Objekterkennung arbeitet ähnlich wie die Tagging-API, liefert jedoch die Begrenzungsfeldkoordinaten (in Pixel) für jedes im Bild gefundene Objekt zurück. Enthält ein Bild beispielsweise ein Reh, ein Wildschwein und eine Person, listet Funktion „detectedObject“ diese Objekte mit ihren Koordinaten im Bild auf. Du kannst also beispielsweise mit dieser Funktion die Beziehungen zwischen den Objekten in einem Bild verarbeiten oder z. B. feststellen, ob sich in einem Bild mehrere Instanzen desselben Objekts befinden.
Die Objekterkennung wendet Tags auf Basis der im Bild identifizierten Objekten oder Lebewesen an, es gibt aber keine formale Beziehung zwischen der Tagging-Taxonomie und der Objekterkennungs-Taxonomie. Konzeptionell findet die Objekterkennungsfunktion ausschließlich Objekte oder Lebewesen, während die Tag-Funktion auch kontextbezogene Begriffe enthalten kann, welche sich nicht mit Begrenzungsboxen lokalisieren lassen.
foreach (DetectedObject detectedObject in result.Objects.Values)
{
Console.WriteLine($" \"{detectedObject.Tags[0].Name}\"");Erkennen und Lokalisieren von Personen mit Hilfe von Azure AI Vision
Eine weitere bestimmte und spezifische Form der Computer Vision ist die Personenerkennung. Die Funktion ermöglicht es, einzelne Personen innerhalb eines Bildes zu identifizieren und deren Standort ebenfalls mit Hilfe einer passenden Begrenzungsbox anzuzeigen.
Ergänze dazu in der Funktion „AnalyzeImage” ab dem Kommentar „Get people in the image“ folgenden Programmcode.
// Get people in the image
if (result.People.Values.Count > 0)
{
Console.WriteLine($" People:"); // Prepare image for drawing
System.Drawing.Image image = System.Drawing.Image.FromFile(imageFile);
Graphics graphics = Graphics.FromImage(image);
Pen pen = new Pen(Color.Cyan, 3);
Font font = new Font("Arial", 16);
SolidBrush brush = new SolidBrush(Color.WhiteSmoke);
foreach (DetectedPerson person in result.People.Values)
{
// Draw object bounding box
var r = person.BoundingBox;
Rectangle rect = new Rectangle(r.X, r.Y, r.Width, r.Height);
graphics.DrawRectangle(pen, rect); // Return the confidence of the person detected//Console.WriteLine($" Bounding box {person.BoundingBox.ToString()}, Confidence:
{person.Confidence:F2}"); } // Save annotated imageString output_file = "persons.jpg";
image.Save(output_file);
Console.WriteLine(" Results saved in " + output_file + "\n");
}Speichere erneut deine Änderungen und führe das Programm mittels „dotnet run“ mit geeignetem Bildmaterial aus, indem du die zugehörigen Pfade jeweils im Programmcode verknüpfst. Du kannst das Programm vergleichsweise auch mit Bildern testen, die keine Personen enthalten. Auch hier wird wieder eine Datei im selben Ordner wie deine Programm-Datei generiert, um die erkannten Personen anzuzeigen. Diese heißt diesmal „persons.jpg“.
Im Falle von Personen könntest du dich jetzt fragen, wo der Unterschied zwischen dem Erkennen von Personen (als Objekte im Bild) und Personen als „Personen“ ist. Der folgenden Ergebnis-Screenshot illustriert das eindrucksvoll. Bei der Personen-Erkennung reagiert die KI offensichtlich präziser und erkennt auch die dritte verdeckte Person im Bild:
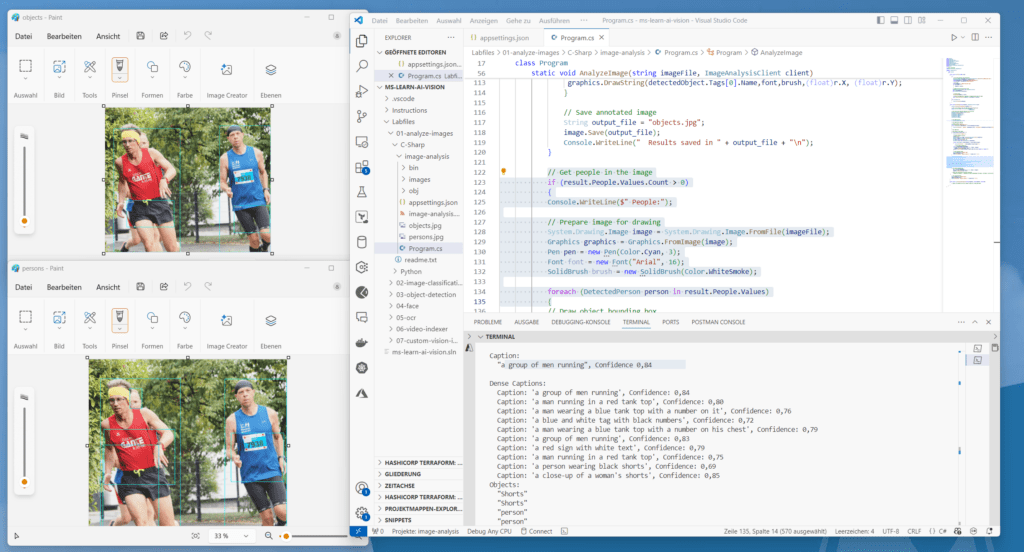 Unterschiede zwischen Objekt- und Personenerkennung mit Azure AI Vision finden
Unterschiede zwischen Objekt- und Personenerkennung mit Azure AI Vision finden
Microsoft hat sein Modell für die Personenerkennung durch Verbessern seines Objekterkennungsmodells in Bezug auf Szenarien zur Personenerkennung erstellt. Bei der Personenerkennung ist das Modell in der Lage, ein Gesicht von einem anderen Gesicht zu unterschieden, Gesichtsattribute vorherzusagen oder zu klassifizieren, sowie eine Gesichtsvorlage zu erstellen. Das Feature Personenerkennung ist jedoch nur in Version 4.0 der Analyze-Image-API enthalten. Man verwendet dabei die Option „People“ in der Abfrage-Parametern für „Features“.
Die wichtigsten URI-Paramater für den Aufruf der Image-Analyze-API sind übrigens:
Name | In | Required |
| Description |
api-version | query | True | string | Angeforderte API-Version |
features | query | VisualFeature[] | Die angeforderten visuellen Features: tags, objects, caption, denseCaptions, read, smartCrops, people. Dieser Parameter muss angegeben werden, wenn der Parameter „model-name“ nicht angegeben wird. | |
language | query | string | Die gewünschte Sprache für die Ausgabegenerierung. Wenn dieser Parameter nicht angegeben wird, ist der Standardwert „en“. | |
model-name | query | string | Der Name des benutzerdefinierten trainierten Modells. Dieser Parameter muss angegeben werden, wenn der Parameter „features“ nicht angegeben wird. |
Mehr Details dazu findest du übrigens in der API-Dokumentation unter https://learn.microsoft.com/de-de/rest/api/computervision/image-analysis/analyze-image?view=rest-computervision-v4.0-preview%20(2023-04-01)&tabs=HTTP
Freistellen von Bildern mit Azure AI Vision
Der Azure AI Vision-Dienst eignet sich auch hervorragend zum Freistellen von Bildern, also dem Entfernen des Hintergrundes. Dazu ergänzt du in deiner Programm-Datei beim Kommentar „// Remove the background from the image or generate a foreground matte“ folgendes Code-Schnipsel:
// Remove the background from the image or generate a foreground matteConsole.WriteLine($" Background removal:");
// Define the API version and modestring apiVersion = "2023-02-01-preview";
string mode = "backgroundRemoval"; // Can be "foregroundMatting" or "backgroundRemoval"
string url = $"computervision/imageanalysis:segment?api-version={apiVersion}&mode={mode}";// Make the REST callusing (var client = new HttpClient())
{
var contentType = new MediaTypeWithQualityHeaderValue("application/json");
client.BaseAddress = new Uri(endpoint);
client.DefaultRequestHeaders.Accept.Add(contentType);
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", key);
var data = new
{
url = $https://github.com/MicrosoftLearning/mslearn-ai-vision/blob/main/Labfiles/01-
analyze-images/Python/image-analysis/{imageFile}?raw=true
};
var jsonData = JsonSerializer.Serialize(data);
var contentData = new StringContent(jsonData, Encoding.UTF8, contentType);
var response = await client.PostAsync(url, contentData);if (response.IsSuccessStatusCode) {
File.WriteAllBytes("background.png", response.Content.ReadAsByteArrayAsync().Result);
Console.WriteLine(" Results saved in background.png\n");
}
else{
Console.WriteLine($"API error: {response.ReasonPhrase} - Check your body url, key, and
endpoint.");
}
}Du kennst das Spiel jetzt schon. Speichere deine Änderungen, füge oben den Pfad für freizustellendes Bild ein und führe das Programm mit „dotnet run“ aus. Im Ergebnis findest du im Programm-Ordner eine weitere Datei „background.png“ von Typ „*.png“. Im folgenden Screenshot siehst du ein Beispiel-Foto und das freigestellte Ergebnis in der Datei background.png mit Microsofts Satya Nadella.
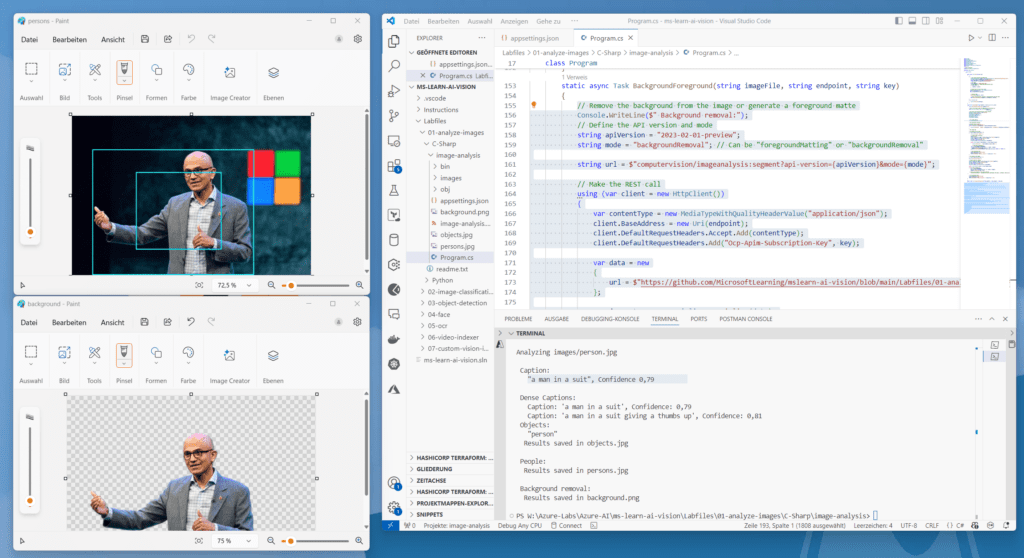 Das KI-basierte Freistellen von Objekten in Bildern vom Hintergrund, meist bei Personen genutzt
Das KI-basierte Freistellen von Objekten in Bildern vom Hintergrund, meist bei Personen genutzt
Aus Datenschutzgründen konnte ich bei Personenfotos nur ein genehmigtes Bild einer bekannten Person des öffentlichen Lebens verwenden. Die Freistell-Funktion kommt hauptsächlich bei Personen und Porträts zum Einsatz.
Du musst die Beispiele nicht abtippen. Die Quellcode-Fragmente findest du in diesem Markdown-File: https://github.com/MicrosoftLearning/mslearn-ai-vision/blob/main/Instructions/Exercises/01-analyze-images.md
Schulungen, die dich interessieren könnten