vSphere 8: Die Neuerungen von VMware
vSphere 8 rockt mit Performance-Boosts, smarter Verwaltung und erweiterter Sicherheit. Bereit für das Upgrade?

VMware hat im Rahmen der VMware Explore 2022 (US) in San Francisco (der ehemaligen VMworld) u. a. auch die kommende Version 8 von vSphere und vSAN vorgestellt. Offiziell erscheinen sollen Beide voraussichtlich im Herbst dieses Jahres. Die interessantesten Neuerungen beleuchtet dieser Beitrag.
Du benötigst einen fundierten Einstieg in vSphere 8? Dann empfehlen wir dir unsere Schulung VMware vSphere: Install, Configure, Manage [V8].
Herausragend an vSphere 8 ist eine neue virtuelle Hardwarefunktion DVX (Device Virtualization Extensions), welche die Grenzen der Plattform erneut verschiebt. In früheren Versionen von vSphere war die Mobilität von VMs, die physische Hardwaregeräte mit Direktpfad-I/O nutzten, eingeschränkt. DVX führt eine neue API und ein neues Framework für Anbieter ein, das hardwaregestützte virtuelle Geräte mit vMotion, DRS, HA oder Suspend and Resume vereinbart macht. DVX unterstützt auch Festplatten- und Speicher-Snapshots, sofern ein DVX-Treiber auf ESXi und gleichzeitig auf VM-Ebene installiert wird.
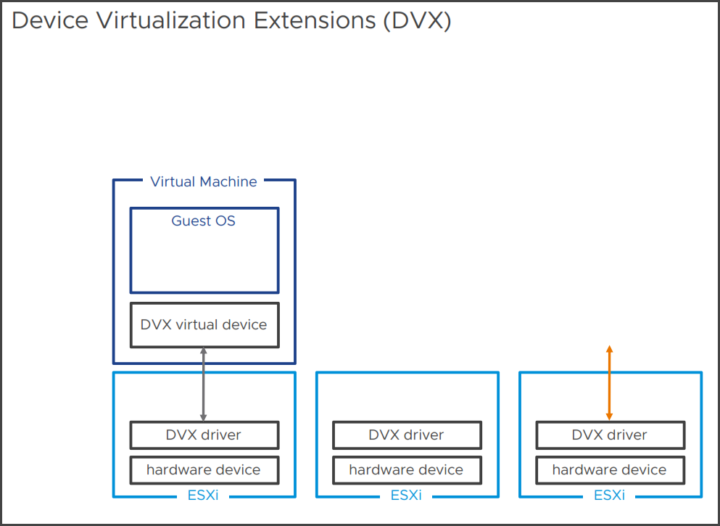 DVX verschiebt die Grenzen von DirectPath I/O
DVX verschiebt die Grenzen von DirectPath I/O
DVX baut auf DirectPathIO auf und führt eine API für Anbieter ein, die es ermöglicht, Virtualisierungsfunktionen zu erstellen, darunter vMotion, Suspend & Resume oder Festplatten- und Speicher-Snapshots. Im Wesentlichen bedeutet dies, dass VMs, die in Zukunft DirectPath I/O verwenden, mehr Virtualisierungsfunktionen (vMotion usw.) nutzen können, anstatt an den zugrunde liegenden Host gebunden zu bleiben. Mehr dazu im Verlauf des Beitrages. Da die Funktion wie die meisten anderen Neuerungen unmittelbar mit der neuen virtuellen Hardware-Version 20 im Zusammenhang steht, schauen wir zunächst auf Diese.
Virtuelle Hardwareversion 20
Die neue virtuellen Hardware-Ebene 20 bringt unter anderem neue Funktionen für ML-Beschleuniger mit, etwa in Form einer Erhöhung der unterstützten DirectPath-I/O-Geräte von 16 auf 32. Natürlich unterstützt die Version 20 die neuesten Intel- und AMD-CPUs. Die maximale Anzahl von VMs pro Cluster ist ebenfalls gestiegen, von 8000 auf 10.000 VMs. Zudem kann der Lifecycle Manager jetzt bis zu 1000 Hosts verwalten kann. Die Hardware-Version 20 verbessert damit wie zu erwarten Leistung und Skalierbarkeit. Auch die Unterstützung für das neue Feature „Gerätegruppen“ (siehe unten) ist eine Folge der neuen Hardware-Version, ebenso wie die verbesserte Latenzempfindlichkeit mit HyperThreading (siehe unten). Ferner unterstützt die neue Hardware-Version wieder die neuesten Gastbetriebssysteme und bringt Gastdienste für Anwendungen einschließlich Unterstützung der neuen Sphere DataSets (siehe unten), sowie die neuen anwendungsbezogene Migrationen (siehe unten).
vSphere 8 liefert mehr Power für AI und ML
Was die VMs betrifft, lassen sich Diese gegenüber vSphere 7 zwar nur mit unveränderter Anzahl an vCPUs und vMem bestücken, verkraften jetzt aber mit 8 doppelt so viele virtuelle GPUs, weil VMware mit vSphere 8 KI- und ML-Anwendungen dramatisch beschleunigen will. Dazu hat VMware nach eigener Aussage aktiv mit NVIDIA zusammengearbeitet. Diese Neuerung verbessert das Spektrum der ML-Beschleuniger-Reihe enorm.
Mit Hilfe von vGPUs könnte beispielsweise das Plattformteam oder das MLOPs-Team Workload-Konstrukte wie VMs, oder Container erstellen und dabei partielle GPU-Ressourcen nutzen. Am anderen Ende des Spektrums lassen sich mit Multi-GPU-Konfigurationen ML-Workloads effizient trainieren. VMware bietet diese Technologien bekanntlich sowohl hostlokal als auch remote im Rahmen der VMware Bitfusion-Technologie an, die ein schnelles Anschließen und Trennen von Workloads und Hardwareressourcen ermöglich.
vSphere 8 : Gerätegruppen zum vereinheitlichen Verwalten von AI/ML-Beschleunigern
Ferner unterstützt vSphere 8 nun sogenannte Hersteller-spezifische Gerätegruppen, eine sehr interessante neue Funktion, welche letztlich die Bindung nicht nur von Hochgeschwindigkeits-Netzwerkgeräten sondern auch von GPUs ermöglicht.
Fest damit im Zusammenhang steht das bereits mit vSphere 7 eingeführte Dynamic DirectPath I/O. Früher musste der Administrator ein GPU-Gerät nach PCI-Standort angegeben. Er musste also stets nachverfolgen, welche ESXi-Hosts welche Geräte bereitstellen können und welche VMs welche Geräte benötigen. Dann musste er eine bestimmte PCI-Adresse auswählen, was die VM z. B. in punkto vMotion einschränkte, weil die VM nur auf diesem spezifischen Host ausgeführt werden konnte. Mit Einführung von Hardwarelabels in vSphere 7 ermöglicht Dynamic DirectPath I/O (DDIO) dem Administrator, die „Art des Geräts“ anzugeben, das einer VM hinzugefügt werden soll.
Das Problem mit DDPIO ist aber, dass es sich trotzdem nur auf ein Gerät bezieht. Mit Version 8 unterstützt vSphere aber das gesamte Spektrum an ML-Beschleunigerkonfigurationen. Was also, wenn ein Data-Science-Team eine Multi-GPU-Konfiguration benötigt? Die Multi-GPU-Konfiguration ist eine infrastrukturelle Betrachtungsweise. Data-Science-Teams sprechen dann von verteiltem Training oder verteiltem Deep Learning. Die Arbeitslastverteilung erfolgt zwischen GPUs innerhalb eines ESXi-Hosts oder über mehrere ESXi-Hosts hinweg. Hier kommen die neuen Gerätegruppen ins Spiel.
Mit Gerätegruppen ermöglicht vSphere 8 dem VI-Administrator oder dem MLOPs-Team, eine Konfiguration für Workloads zu erstellen, die mehrere GPUs erfordern, die über eine Hochgeschwindigkeitsverbindung verbunden sind, oder Geräte, die sich auf demselben PCI-Switch befinden müssen. Diese Gruppen werden dann dem ESXi präsentiert und automatisch von vCenter erkannt, wobei jede Gruppe als einzelne Einheit dargestellt wird, nicht in Form einzelner Geräte.
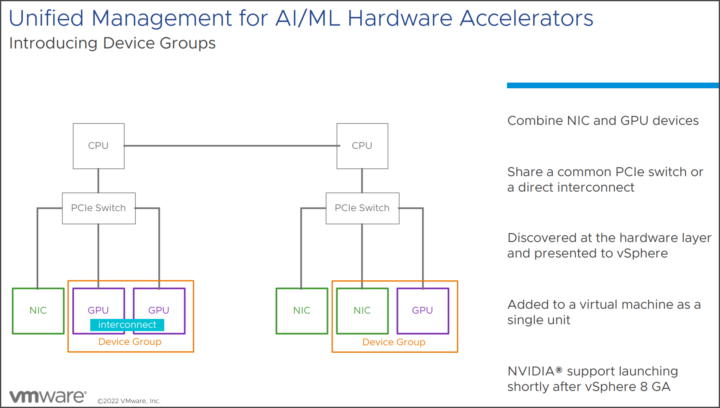 Gerätegruppen kombinieren z. B. NICs mir GPUs oder teilen PCIe-Switche über den QPIC.
Gerätegruppen kombinieren z. B. NICs mir GPUs oder teilen PCIe-Switche über den QPIC.
So kann der Admin nun NIC- und GPU-Geräte kombinieren oder einen gemeinsamen PCIe-Switch oder eine direkte Verbindung nutzen und als einzelne Einheit an VMs anhängen. vSphere HA und DRS erkennen Gerätegruppen, womit sichergestellt ist, dass VMs stets auf Hosts platziert werden, welche die benötigten Gerätegruppen bereitstellen können.
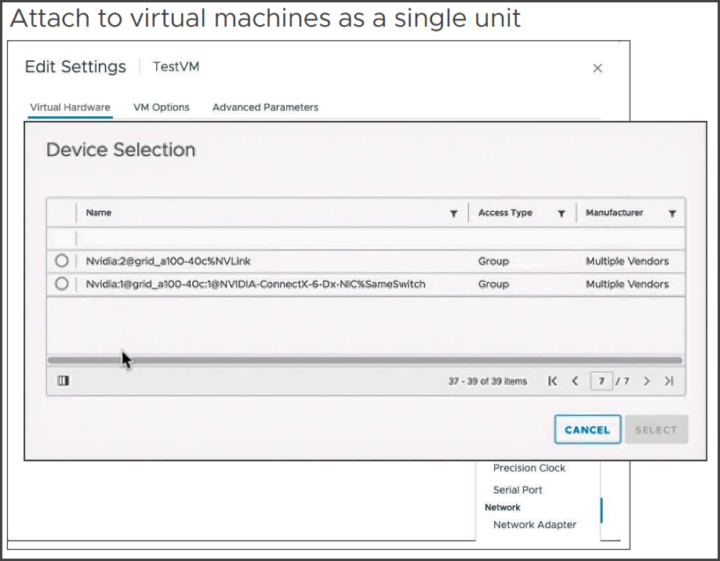 Das Konfigurieren von Gerätegruppen.
Das Konfigurieren von Gerätegruppen.
Verteilte Arbeitslasten, die über GPUs ausgeführt werden, die sich auf mehreren ESXi-Hosts befinden, brauchen allerdings geringstmögliche Latenz. Dabei erhält die Verbindung zwischen den ESXi-Hosts die meiste Aufmerksamkeit, aber auch der Pfad von der GPU zur externen Verbindung ist von entscheidender Bedeutung.
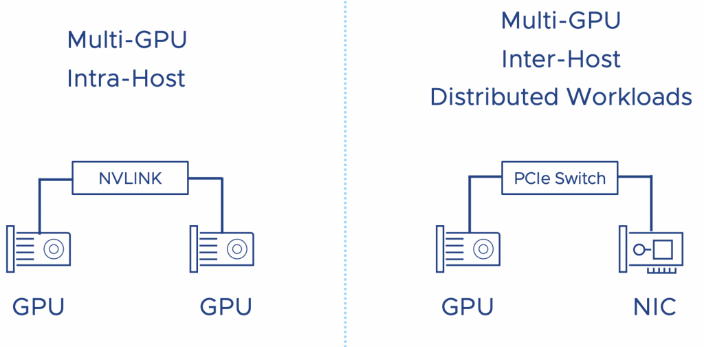 Verteilte GPU-Arbeitslasten via NVLINK (nVidia) oder das Kombinieren von NIC und GPU (PCIe-Switch)
Verteilte GPU-Arbeitslasten via NVLINK (nVidia) oder das Kombinieren von NIC und GPU (PCIe-Switch)
Um die Latenz zu minimieren, muss vSphere die NUMA-Lokalität sowohl der GPU als auch der NIC berücksichtigen. Moderne CPUs haben PCI-Controller in das CPU-Paket eingebaut, sodass NUMA PCI-Lokalität gegeben ist. Um eine konsistente Leistung bereitzustellen muss der Admin also Geräte auswählen, die mit demselben PCI-Controller oder PCI-Switch (in großen Systemen verfügbar) verbunden sind.
So ermöglicht eine Hochgeschwindigkeitsverbindung zwischen GPU-Beschleunigern immer eine stabile, konsistent hohe Bandbreite und stellt die maximale Leistung der verfügbaren lokalen Hardware sicher. NVIDIA beispielsweise bietet mit NVLINK eine direkte GPU-zu-GPU-Verbindung an. Eine nVIDIA A30-Karte z. B. bietet einen Link pro Karte. Ein A100 ist mit drei Verbindungen ausgestattet und bietet eine GPU-zu-GPU-Bandbreite von 150 GB/s, d. h. jeder Link stellt theoretisch 50 GB/s Bandbreite zur Verfügung. Mithilfe der neuen Gerätegruppen können VI-Administratoren des MLOPs-Teams mehrere Geräte als eine Einheit zu einer virtuellen Maschine hinzufügen.
vSphere 8 : Vereinfachte virtuelle NUMA-Konfiguration
Dazu wird die virtuelle NUMA-Topologie in vSphere 8 auch für den vSphere-Client verfügbar gemacht. (In früheren Versionen musste dies über die CLI erfolgen.) Voraussetzung dafür ist ebenfalls die virtuelle Hardware-Version 20. Die Gerätezuweisungsfunktion in der neuen vSphere- 8-GUI zur vNUMA-Topologie hilft VI-Administratoren und MLOPs-Teams, die vCPU und GPU einer VM demselben NUMA-Knoten zuzuweisen. Damit verbessert die Funktion die Möglichkeit, dass der Arbeitsspeicher der VM auf dem gleichen NUMA-Knoten wie die GPU bleibt. Nutzer können das Verhalten in Verlauf des Assistenten zum Erstellen neuer VMs konfigurieren oder die CPU-Topologie-Einstellungen der vorhandenen VM bearbeiten.
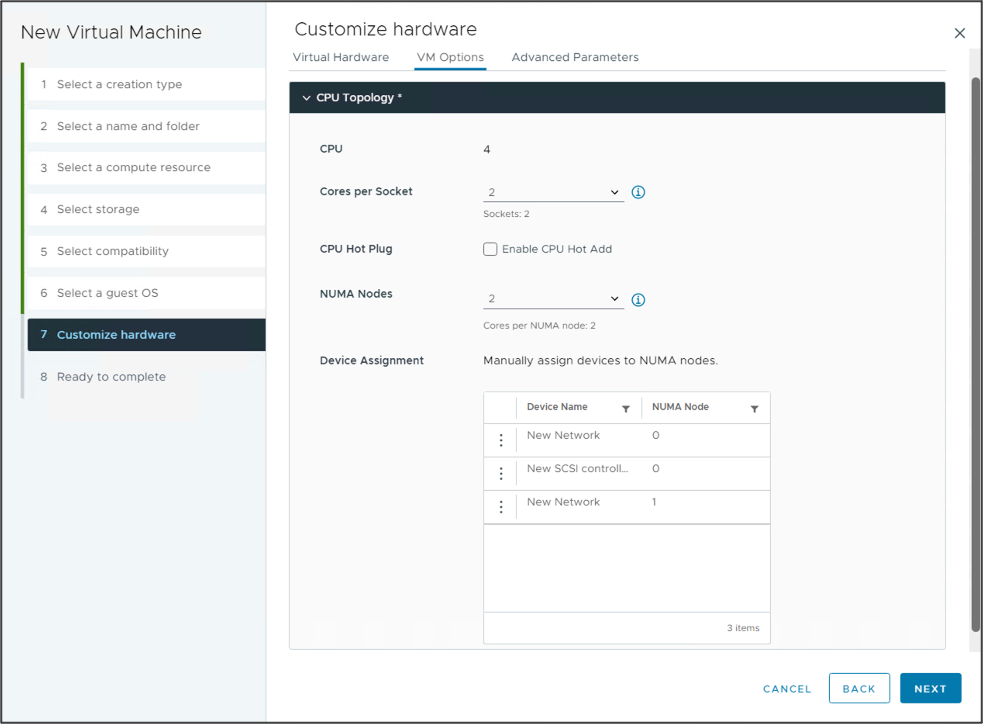 Virtuelles NUMA im vSphere-Client.
Virtuelles NUMA im vSphere-Client. 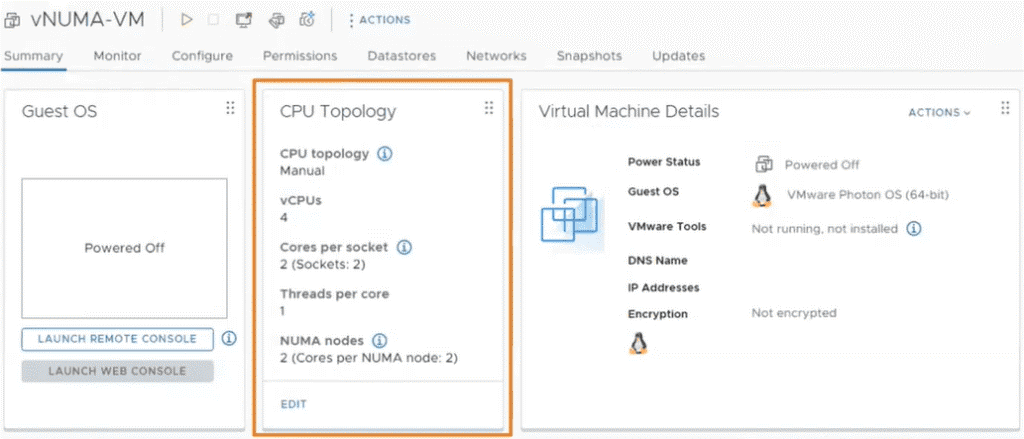 Die CPU-Topologie aus Sicht der VM.
Die CPU-Topologie aus Sicht der VM.
vSphere-Datasets
Die oben erwähnten Datasets in vSphere 8 stellen eine neue Methode zum Teilen von (Konfigurations)Daten zwischen vSphere und dem Gastbetriebssystem dar, wobei Daten mit der VM gespeichert und verschoben werden können. Potenzielle Anwendungsfälle wären z. B. der Gast-Bereitstellungsstatus, die Gast-Agent-Konfiguration oder die Gast-Bestandsverwaltung sein. Der Mechanismus funktioniert mit installierten VMware-Tools. Außerdem benötigt es die virtuelle Hardwareversion 20.
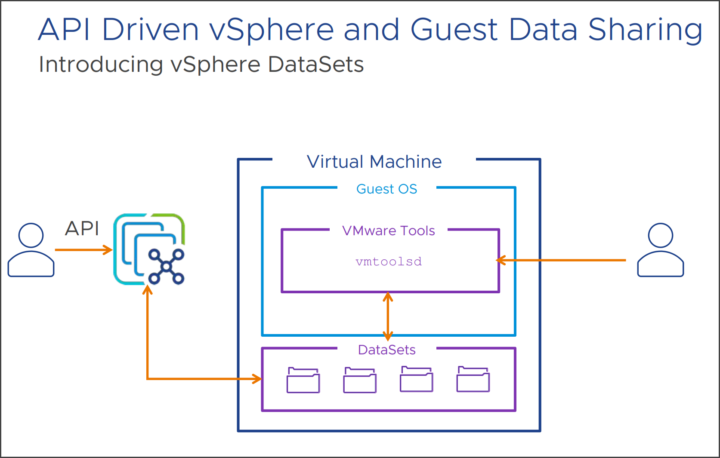 Die neuen Datasets in vSphere 8.
Die neuen Datasets in vSphere 8.
Windows 11 Virtual TPM-Bereitstellungsrichtlinie
Das Problem mit TPM und dem Klonen von VMs besteht darin, dass es ein Sicherheitsrisiko darstellen kann. Aus diesem Grund hat VMware eine neue Funktion eingeführt, mit der der Admin angeben kann, ob er das TPM-Gerät kopieren oder ersetzen möchten.
Während des Klonens der vorhandenen VM kann er die Option „Ersetzen“ auswählen und die VM wird mit einem brandneuen TPM-Gerät erstellt, das keinen Zugriff auf die Geheimnisse der Quell-VM hat.
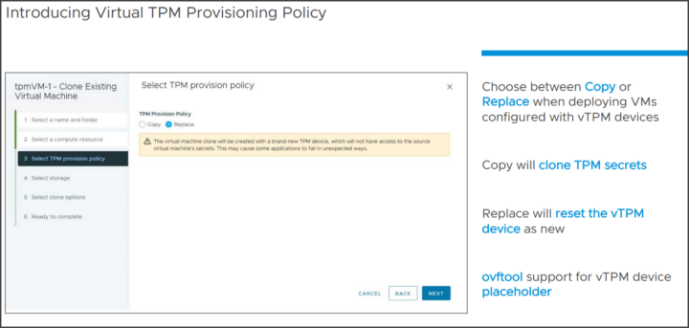 Beim Klonen einer vorhandenen VM kann nun trotzdem ein neues TPM erstellt werden.
Beim Klonen einer vorhandenen VM kann nun trotzdem ein neues TPM erstellt werden.
Migrationsfähige Anwendungen
In der Vergangenheit funktionierten bestimmte Arten von Anwendungen, insbesondere zeitkritische VOIP- oder geclusterte Anwendungen, nicht gut mit vMotion. Anwendungen können jetzt so geschrieben werden, dass sie vMotion-fähig sind, sodass z. B. bestimmte Dienste vor dem Start einer vMotion-Operation gestoppt und danach wieder fortgesetzt werden. Alternativ könnte die Anwendung auf ein anderes Clustermitglied umschalten und den Beginn eines vMotion-Vorgangs bis zu einem bestimmten Punkt verzögern. Konkret verzögert die Anwendung selbst die Migration bis zu einem konfigurierbaren Timeout verzögern, aber sie kann die Migration nicht stoppen.
vSphere 8 : Latenzempfindliche Anwendungen
Die ebenfalls in vSphere 8 neue Latenzempfindlichkeit mit Hyperthreading ermöglicht die Planung der vCPUs von VMs auf demselben physischen CPU-Kern mit Hyperthreading. Der physische Host muss Hyperthreading unterstützen. Auch diese Funktion benötigt die neueste virtuelle Hardware 20. Außerdem muss der Admin für diese VM eine CPU- und Arbeitsspeicherreservierung von 100 % festlegen. Die VM ist optimiert, um die Anforderungen an niedrige Latenzen latenzempfindlicher Anwendungen zu erfüllen. Jeder virtuellen CPU wird exklusiver Zugriff auf einen Thread auf einem physischen Kern gewährt.

Kubernetes / Tanzu
Nachdem es zuletzt mehrere Varianten von vSphere mit Tanzu gab, einschließlich TKG (Supervisor- und Guest-Cluster nur für vSphere), TKGm (Verwaltungs- und Workload-Cluster für Multi-Cloud einschließlich vSphere) vereint VMware in vSphere 8 wieder alle bisherigen Optionen in einer einzigen TKG-Laufzeitumgebung, die überall ausgeführt werden kann.
Ebenfalls neu in Tanzu Kubernetes Grid 2.0(3) sind die so genannten Workload Verfügbarkeitszonen. Hierbei handelt es sich um eine neue Funktion mit der der Admin Workloads über vSphere-Cluster isolieren kann. Supervisor- und Tanzu Kubernetes-Cluster können dann in diesen Zonen bereitgestellt werden. Dadurch ist sichergestellt, dass sich Worker-Knoten nicht in denselben vSphere-Clustern befinden, was letztendlich die Verfügbarkeit verbessert.
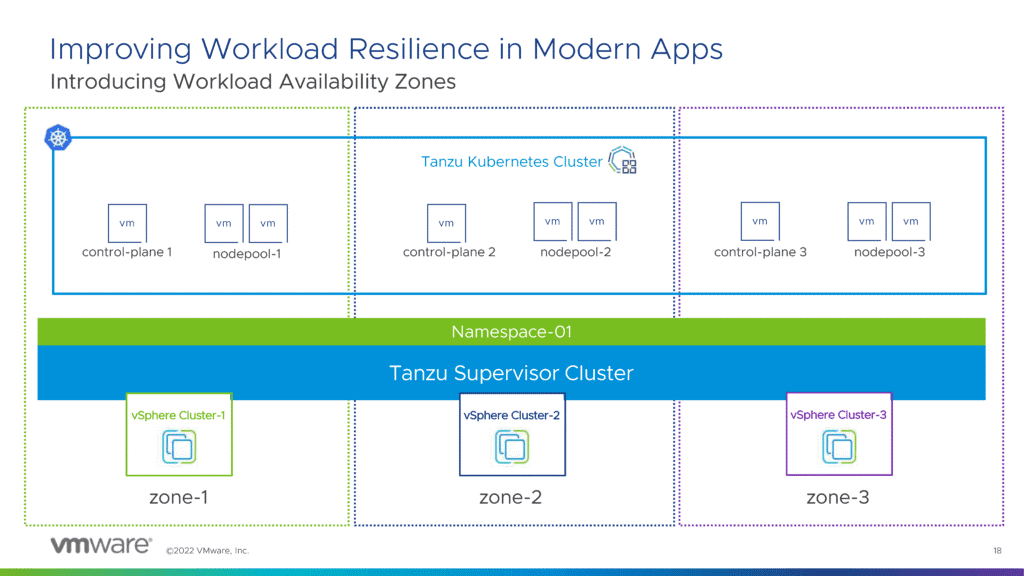 Verfügbarkeitszonen für Tanzu in vSphere 8.
Verfügbarkeitszonen für Tanzu in vSphere 8.
Ferner bietet der neue Cloud Consumption Interface-Service in vSphere 8 Entwicklern und DevOps-Ingenieuren einen Kubernetes-basierten gemeinsamen API-Endpunkt und eine Benutzeroberfläche, die einen schnellen und einfachen Zugriff auf IaaS-Services in der gesamten VMware Cloud b bereitstellen.
Die neuen Funktionen für vSAN 8 behandelt wir in einem separaten Artikel behandelt.
Schulungen, die dich interessieren könnten