Azure AI Gesichtserkennung (Teil 3)

Azure AI Computer Vision, Gesichtserkennungs-API und Custom Vision
Wir haben uns bereits allgemein mit der Bilderkennung im Rahmen der Azure KI-Services befasst und für mehr Übersicht im Portfolio der Azure-KI-Services gesorgt. Dieser Artikel vertieft das Thema maschinelles Sehen mit Azure AI Vision auf die beteiligten Algorithmen für das Feature Gesichtserkennung. Für den optimalen Einstieg empfehlen wir dir unsere Azure KI Schulungen.
Passende Schulungen
AI-3004 – Erstellen von Lösungen für maschinelles Sehen mit Azure KI Vision

AI-900 – Microsoft Azure AI Fundamentals (AI-900T00)
AI-900 – Microsoft Azure AI Fundamentals (AI-900T00): Einführung in künstliche Intelligenz (AI) und Grundlagen von AI in Azure
Azure AI Gesichtserkennung – das solltest du kennen
Wie schon im einführenden Artikel erläutert, umfasst das KI-Thema sowohl mathematisch wissenschaftliche Aspekte (Date Science), als auch, z. B. aus Sicht des Entwicklers, Erfahrung in der Modellierung von künstlicher Intelligenz in Software, sowie aus Perspektive des Azure-Administrators Kenntnisse über das Portfolio der Azure-KI-Dienste einschließlich der verfügbaren Werkzeuge wie z. B. dem Azure VisionStudio oder der von Azure bereitgestellten API. Möchtest du als Unternehmen entsprechende Services in deine Produkte integrieren müssen Entwickler, Datenwissenschaftler und Azure-Spezialisten zusammenarbeiten. In diesem Beitrag versetzen wir uns zwar in die Perspektive des Entwicklers, nutzen aber zunächst das VisionStudio, um die Arbeitsweise und Leistungsfähigkeit der von Microsoft bereitgestellten, vortrainierten Modelle zur Gesichtserkennung auszuprobieren.
Bildmanipulation versus maschinelles Sehen
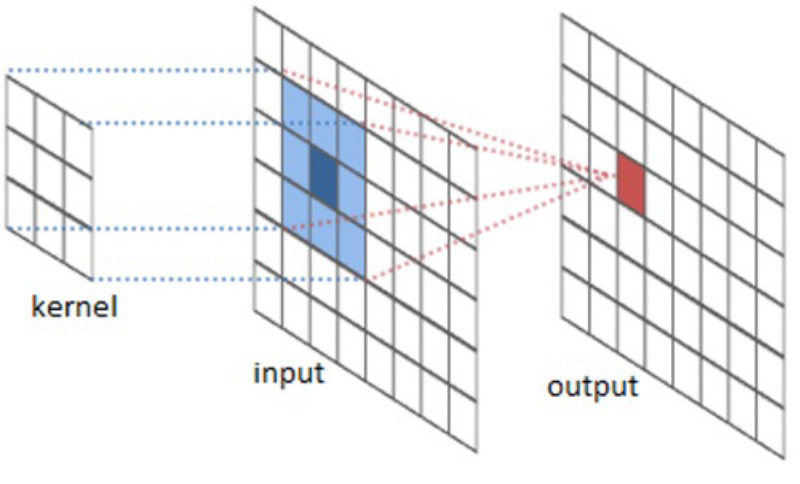
Um zu verstehen, wie Bilderkennung und Analyse mit Hilfe KI-gestützter Algorithmen funktionieren sei an ein paar Grundlagen der digitalen Bildverarbeitung erinnert. Für Computer ist ein Bild nichts anderes als ein numerisches Pixel-Array, wobei jedes Pixel Werte zwischen 0 (schwarz) und 255 (weiß) annehmen kann. Dabei definiert ein zweidimensionales Array praktisch ein Graustufenbild. Farbbilder dagegen sind multidimensional und bestehen aus drei, als „Kanäle“ bezeichnete Ebenen, welche dann rote, grüne und blaue (RGB) Farbtöne darstellen. Zu üblichen Verfahren des Ausführens von Bildverarbeitungsaufgaben gehört das Anwenden von Filtern auf ein solches Array. Dadurch werden die Pixelwerte des Bildes geändert, um einen visuellen Effekt zu erzeugen. So ein Filter definiert sich dabei durch ein oder mehrere Arrays von Pixelwerten, auch als „N x N-Filterkerne“ bezeichnet, die über das Ausgangsbild gefaltet werden.
Quelle: https://intellabs.github.io/RiverTrail/tutorial/
Im Verlauf dieses „Falt“-Prozesses wird je nach Art des Filters z. B. eine gewichtete Summe für jeden NxN-Abschnitt berechnet und das Ergebnis einem neuen Bild zugeordnet.
Ein solcher Prozess wird dann so oft wiederholt, bis der Filter über das gesamte Bild hinweg „zusammengedreht“ (gefaltet) ist. Beim Berechnen des neuen Werte-Arrays könnten sich durchaus einige der Werte außerhalb des Wertebereichs von 0 bis 255 Pixeln befinden und werden daher automatisch angepasst. Filter, die sich wie beschrieben über das gesamte Bild ausdehnen heißen in der digitalen Bildmanipulation auch „konvolutionale Filter“. Ein bekannter Filtertyp dieser Kategorien z. B. zum Betonen von Kanten ist beispielsweise der „Laplace-Filter“. Andere Filter-Arten sind beispielsweise geeignet zum Schärfen, Weichzeichnen oder Inversiren von Farben.
Zwar ist die Anwendbarkeit von Effekten auf Bilder in der Bildverarbeitung an sich nützlich, beim maschinellen Sehen geht es jedoch mehr darum, Bedeutungen zu erkennen, um Erkenntnisse aus Bilderinhalten zu gewinnen. Dazu bedarf es wiederrum des Einsatzes von Machine-Learning-Modellen, welche auf Basis großer Mengen vorhandener Bilder dazu trainiert wurden, bestimmte „Merkmale“ zu erkennen. Ein sehr häufig anzutreffender Typ neuronaler Netze, der z. B. bei der Bildklassifizierung zum Einsatz kommt, ist ein so genanntes konvolutionales neuronales Netzwerk (Convolutional Neural Network = CNN).
Passende Schulungen
AI-102 – Designing and Implementing a Microsoft Azure AI Solution (AI-102T00)
Konvolutionale neuronale Netzwerke (CNN)
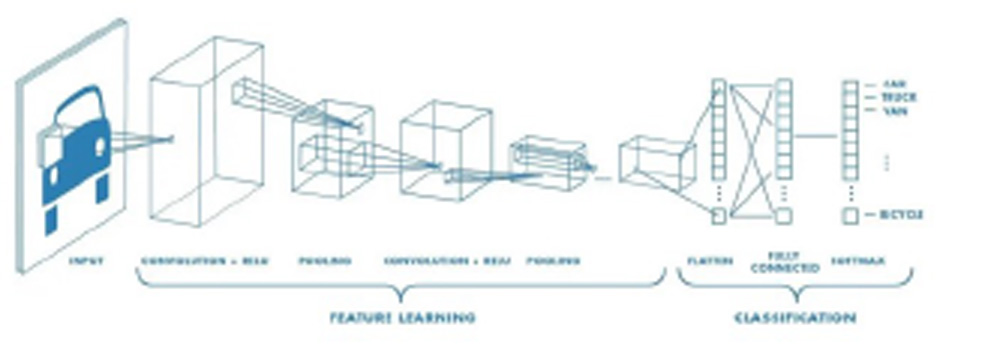
CNNs nutzen zunächst Filter, die numerische Merkmalszuordnungen aus Bildern extrahieren. Erst danach werden die Merkmalswerte in ein Deep Learning-Modell eingespielt, welches dann Vorhersagen für Bezeichnungen generiert. Geht es beispielsweise um eine Bildklassifizierung, könnte die Bezeichnung das dominierende Thema des Bildes sein (was zeigt das Bild?). Im Verlauf des Trainingsprozesses eines CNN werden zuerst verschiedene Filterkerne unter Zuhilfenahme zufällig generierter Gewichtungswerte definiert. Mit Fortschreiten des Trainingsprozesses werden die Modellvorhersagen anhand bekannter Bezeichnungswerte ausgewertet und damit die Filtergewichte angepasst, was die Genauigkeit verbessert.
Das fertig trainierte Bildklassifizierungsmodell verwendet die Filtergewichte, die am besten Merkmale zur Identifizierung verschiedener Arten des zu klassifizierenden Objektstyps extrahieren können. Der Begriff “Convolution” im CNN bezieht sich auf die mathematische Funktion der Faltung. Dabei handelt es sich um eine spezielle Art von linearer Operation, bei der zwei Funktionen multipliziert werden, um eine dritte Funktion zu erzeugen. Diese beschreibt, wie die Form einer Funktion durch die andere modifiziert wird. In einfachen Worten: Zwei Bilder, die als Matrizen dargestellt werden können, werden multipliziert, um eine Ausgabe zu erzeugen, die zur Extraktion von Merkmalen aus dem Bild verwendet wird.
Quelle: https://saturncloud.io/
Transformer
Seit vielen Jahren schon bilden solche CNN das Fundament für viele Lösungen für maschinelles Sehen und werden in diesem Zusammenhang oft zur Bildklassifizierung eingesetzt, aber auch für komplexere Modelle für maschinelles Sehen etwa zur Objekterkennung. Allerdings hat sich in anderen KI-Disziplinen der linguistischen Datenverarbeitung (Natural Language Processing, NLP) eine andere Art neuronaler Netzarchitektur durchgesetzt, die allgemein als „Transformer“ oder „Transformator“ bezeichnet wird. Transformer erlauben die Entwicklung anspruchsvoller Modelle für Sprache. Transformer basieren auf der Verarbeitung riesiger Datenmengen in Form codierter Sprach-Token, welche entweder einzelne Wörter oder Ausdrücke darstellen und als vektorbasierte Einbettungen (Arrays numerischer Werte) dargestellt werden. Jede Einbettung kann man sich quasi als Darstellung einer Reihe von Dimensionen vorstellen, von denen jede ein semantisches Attribut des Tokens darstellen. Dabei erstellen die Entwickler solcher Modelle Einbettungen derart, dass Token, die häufig im selben Kontext verwendet werden, dimensional „näher“ beieinander liegen, weil semantisch ähnlich Token an ähnlichen Positionen codiert sind. So ein semantisches Sprachmodell ermöglicht es, anspruchsvolle NLP-Lösungen für Textanalyse, Übersetzung, Sprachgenerierung und andere Aufgaben zu erstellen.
Da sich Transformer als sehr effizient beim Erstellen von Sprachmodellen erwiesen haben, kam in der KI-Forschung die Idee auf, den gleichen Ansatz für Bilddaten zu nutzen, was im Ergebnis zur Entwicklung multimodalen Modelle führte, bei denen das Modell mit einem großen Volumen von beschrifteten Bildern trainiert wird, allerdings ohne feste Bezeichnungen. Ein Bild-Encoder extrahiert dann auf Basis von Pixelwerten Merkmale aus Bildern und kombiniert sie mit Texteinbettungen, welche jedoch von einem Sprach-Encoder erstellt wurden.
Das allgemeine Modell kapselt dann Beziehungen zwischen Token-Einbettungen in natürlicher Sprache und Bildmerkmalen. Das https://azure.microsoft.com/en-us/blog/announcing-a-renaissance-in-computer-vision-ai-with-microsofts-florence-foundation-model/ Florence-Modell vom Microsoft ist ein solches Modell. Es ist seit März 2023 verfügbar.
Lasst uns nun einige Modelle zum Analysieren von Bildern mit dem Azure KI Vision ausprobieren. Azure AI Vision unterstützt mehrere Funktionen zur Bildanalyse, darunter das Extrahieren von Text aus Bildern mittels Texterkennung (OCR), das Generieren von Untertiteln und Beschreibungen anhand des erkannten Inhaltes von Bildern, Erkennung von Tausenden gängiger Objekte in Bildern oder das Markieren visueller Funktionen in Bildern.
Wie schon bei den vorhergehenden Beispielen kannst du dazu wieder wahlweise eine Azure-Ressource von Typ „Azure KI Vision“ oder „Azure KI Services“ erstellen und mit dem Vision Studio verknüpfen:
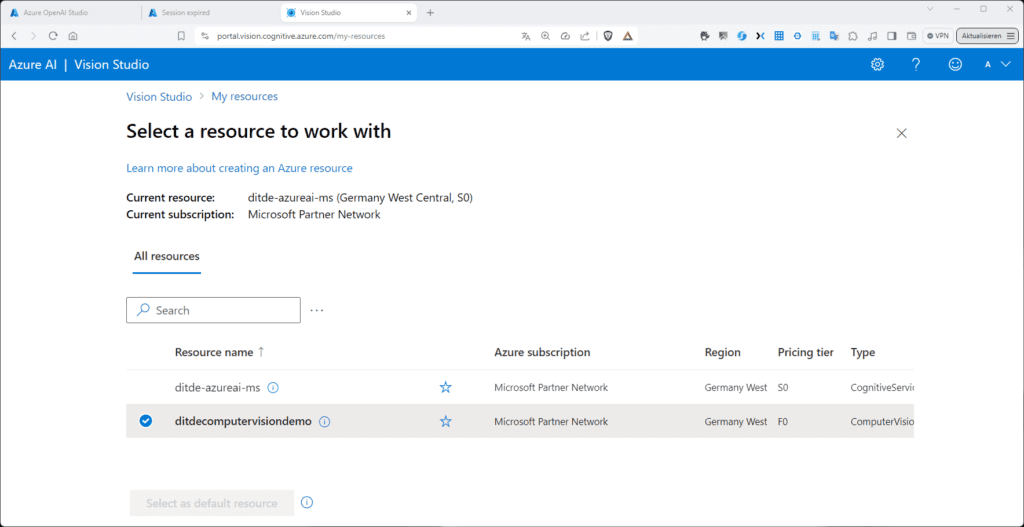
Navigiere im Vision Studio zum Tab „Image analysis“. Hier findest du zahlreiche Modelle und Beispiele.
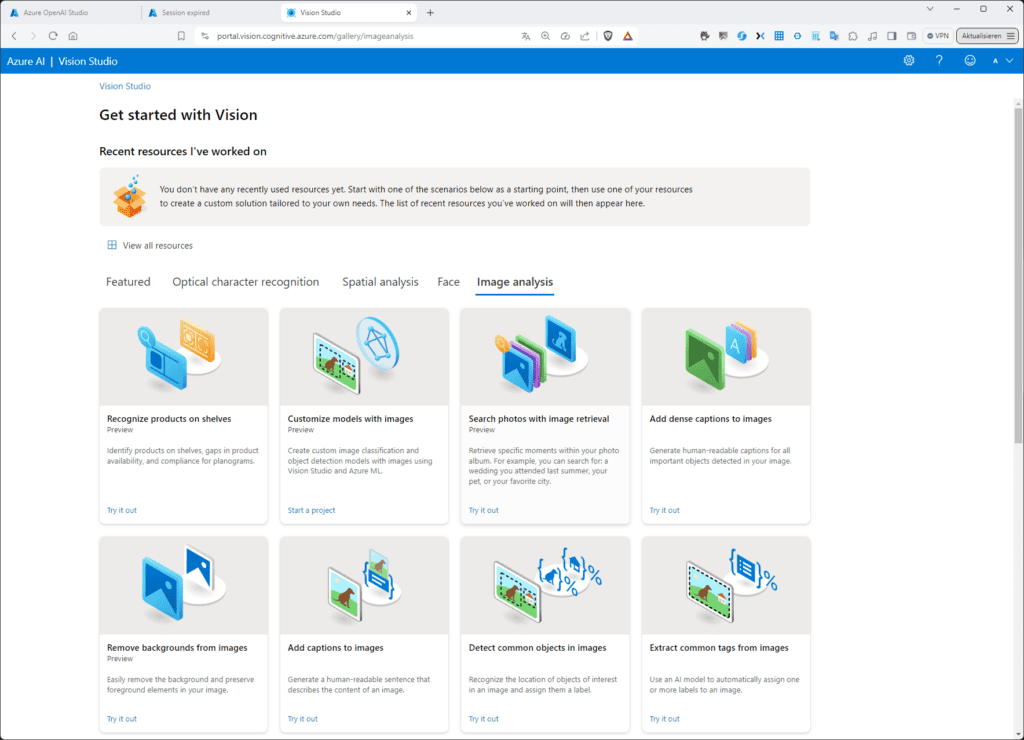
So kannst du z. B. mit dem Modell „Add dense caption to image“ Bildunterschriften auf Basis des erkannten Bildes generieren lassen. Achtung: Dieses Modell ist derzeit nur in einigen Regionen verfügbar, aber nicht in Deutschland.
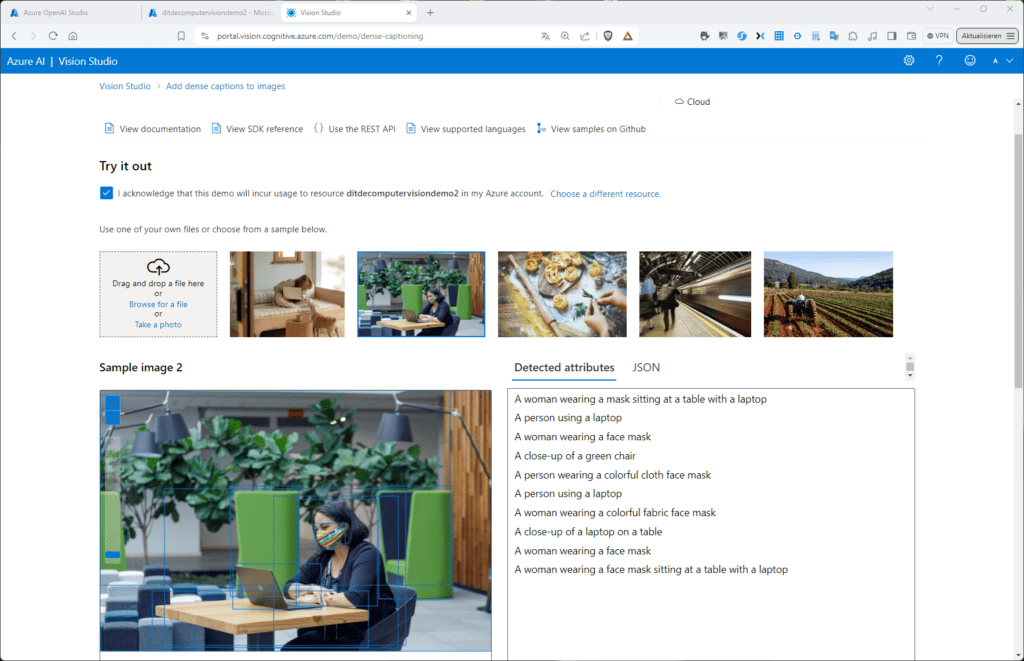
Probiere es mit einem der Beispielbilder aus: Das Modell liefert dir unter „Detected attributes“ eine Reihe von Vorschlägen, jeder passend zu einem der links identifizierten Bereiche, die jeweils durch ein Rechteck gekennzeichnet sind: Markierst du rechts eines der Attribute wird der zugehörige Bereich links orange hervorgehoben.
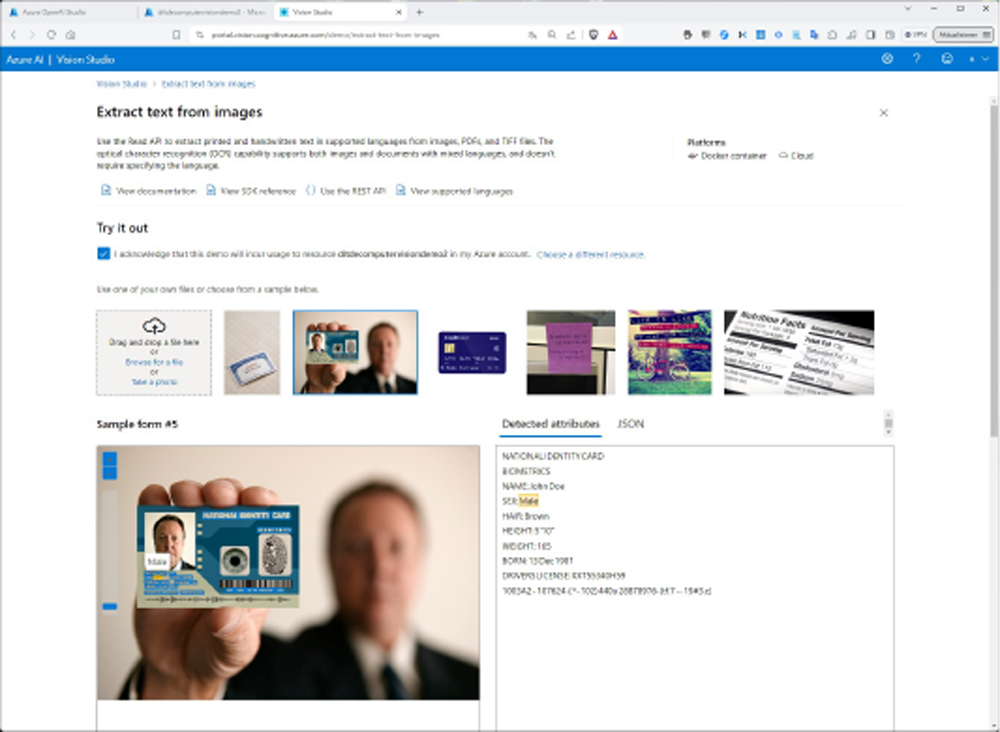
Ebenfalls interessant ist das Modell „Extract text from image“ im Tab „Optical character recognition“. Auch hier testen wir eines der mitgelieferten Beispiele:
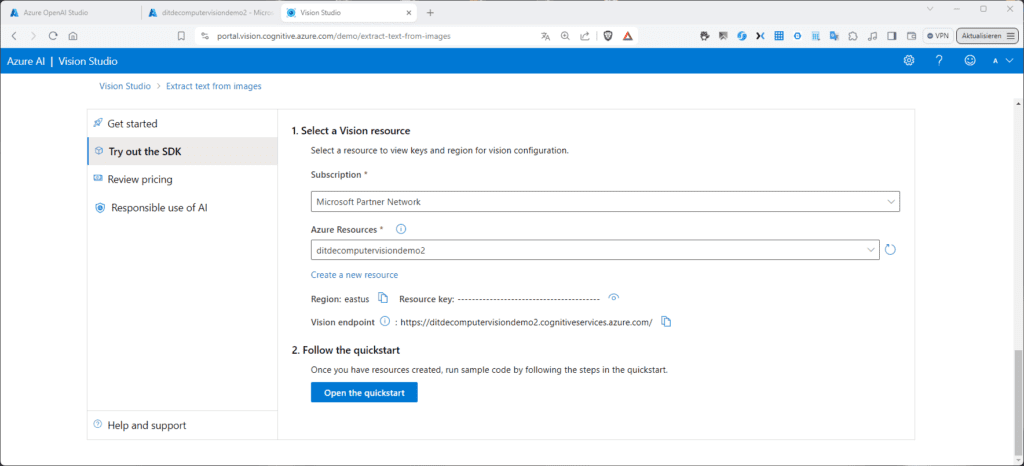
Navigiere nun nach unten zu „Next steps“. Hier hast du beispielsweise wieder die Möglichkeit, das SDK auszuprobieren; Endpunkt und Schlüssel werden hier passenderweise gleich angezeigt.
Kontakt

„*“ zeigt erforderliche Felder an

