vSphere HA – so nutzt du Application Monitoring

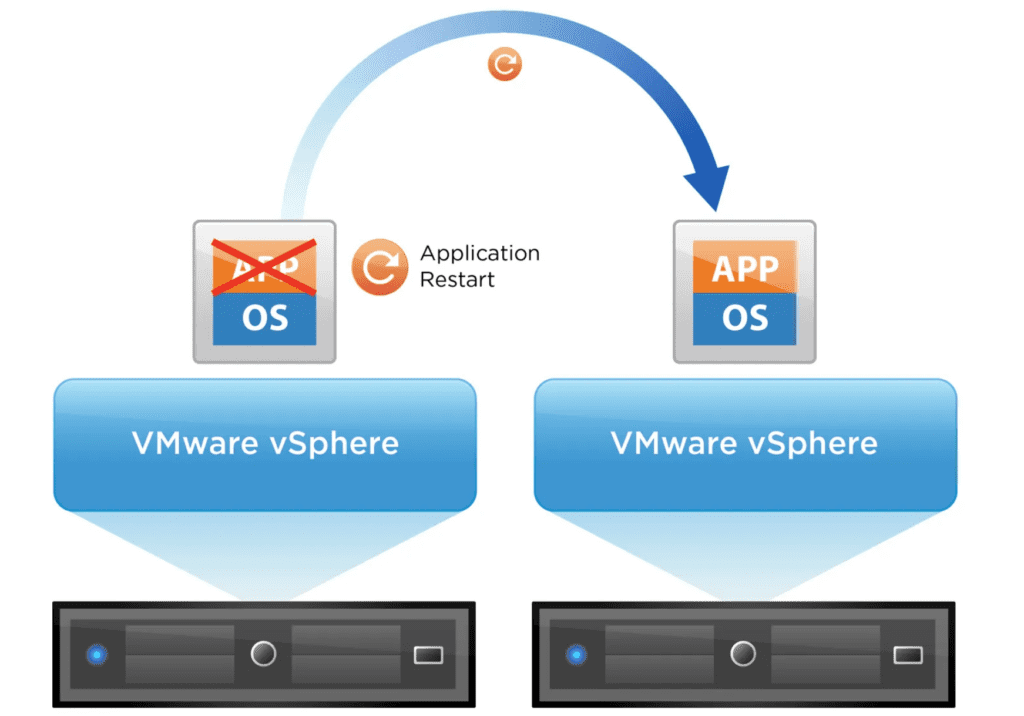
Oft werde ich in meinen VMware vSphere Schulungen gefragt, wie man eigentlich das HA-Feature Application Monitoring nutzt, wie es funktioniert und warum die Nutzung des Features in „freier Wildbahn“ eher selten zu beobachten ist.
Passende Schulungen
VMware vSphere: Fast Track [V8]
VMware vSphere: Fast Track [V8]: Intensives vSphere-Infrastruktur Training
![VMware vSphere: Fast Track [V8]](https://incas-training.de/wp-content/uploads/2021/07/vmware-3-536x268.jpg)
VMware vSphere: Install Configure Manage V8
VMware vSphere: Install, Configure, Manage V8: Aktuelles Wissen über die optimale Nutzung von VMware vSphere V8
vSphere HA: Schutz deiner VMs vor Host-Ausfällen
Primär schützt vSphere HA bekanntlich VMs vor Host-Ausfällen. Dabei ist „Schutz“ im vSphere-Kontext eigentlich das falsche Wort, weil vSphere HA NICHT fehlertolerant ist, im Gegensatz zu vSphere Fault Tolerance. VSphere HA startet VMs, die von einem Host-Ausfall betroffen sind aber umgehend auf einem anderen Host neu, sofern sich deren virtuelle Disks auf einem Shared Storage befinden, was zwingende Voraussetzung für vSphere HA ist. Den Hostausfall bemerkt der Master-Host im HA-Cluster anhand des Ausbleibens von HA-Taktsignalen, welche Master- und Slave-Hosts im HA-Cluster um den VMKernel-Adapter „Management“ austauschen.
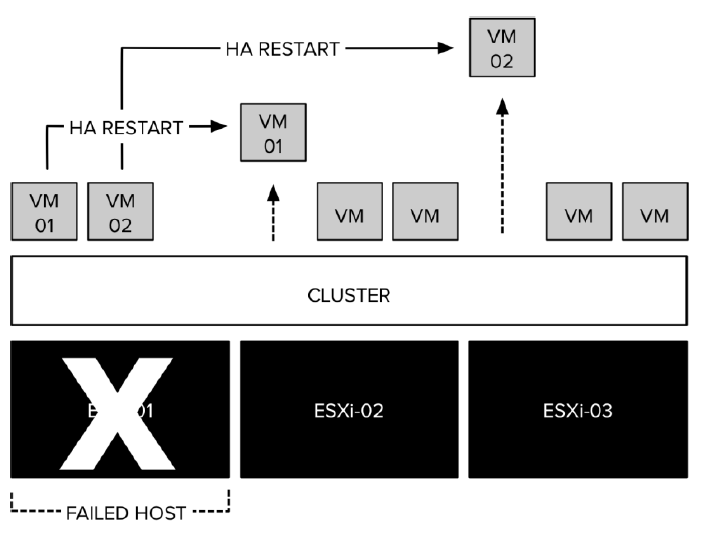
vSphere HA: Weitere Fehler-Szenarien
Über die Jahre hat VMware sein „vSphere HA“, bzw. „ESXi HA“ mit zusätzlichen Funktionen ausgestattet. So kann das Feature heute nicht nur ESXi-Host-Ausfälle erkennen und darauf mit dem Neustarten der betroffenen VMs reagieren, sondern bildet auch andere Fehler-Szenarien in einem ESXi-HA-Cluster ab. So kann z. B. Ausbleiben von HA-Taktsignalen über das Management-Netzwerk auch auf Netzwerkfehler zurückzuführen sein. Der ausgeklügelte Fehlererkennungs-Algorithmus des vSphere-HA-Fault Domain Managers ist aber auch in der Lage, Host-Ausfehler von Netzwerkausfällen (Host-Isolierung oder Netzwerk-Partitionierung) zu unterscheiden, indem er zusätzliche Liveness-Pings mit dem Pingen von extra dazu konfigurierten Isolationsadressen kombiniert.
Im Gegensatz zur Standard-Reaktion „VM neu starten“ beim Host-Fehler, ist die passende Fehler-Antwort bei Netzwerkfehlern aber frei konfigurierbar, weil die „richtige“ Reaktion von den spezifischen Gegebenheiten bzgl. Speicher-Netzwerk, Management-Netzwerk usw. abhängt. Nicht immer ist „VM neu starten“ die richtige Reaktion, falls nämlich die VMs noch laufen, der Host aber keine Taktsignale mehr empfängt.
Seit vSphere 6 kann ESXi-HA auch Datastore-Zugriffsfehler (APD oder PDL) erkennen und voneinander unterscheiden. Das Feature heißt „VM Komponenten Schutz“ (VMCP). Auch in diesem Fall laufen Host und VMs noch, die VMs erreichen aber ihren VMDKs nicht mehr. Hier ist „VMs neu starten“ manchmal (aber nicht immer) die richtige Option. Daher sind alle „Antworten“ auf die verschiedenen Fehler-Szenarien in vSphere HA im vSphere Client konfigurierbar.
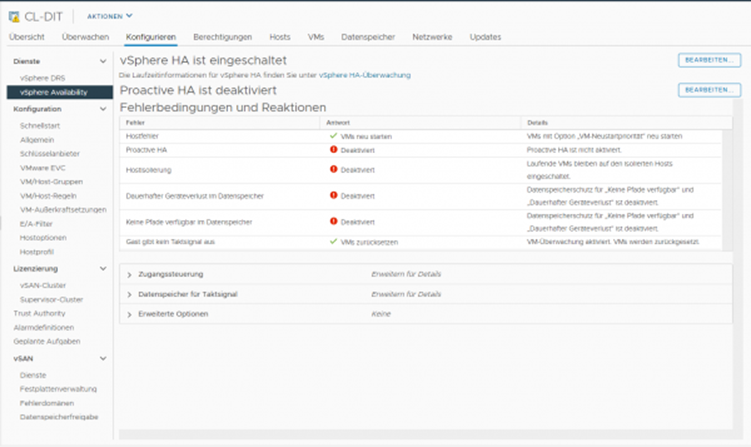
vSphere HA: VM- und Anwendungsschutz
Wie man hier erkennt, gibt es noch zwei weitere Fehler-Szenarien, mit denen vSphere HA umgehen kann, nämlich den direkten Schutz von VMs und Anwendungen. Hier geht es nicht darum, dass VMs ausfallen, weil deren Host betroffen ist, sondern um das Gastsystem und die Anwendung selbst. Hierzu tauschen Gastsystem und Anwendung ebenfalls eine eigene Art von Taktsignalen mit Hilfe der VM-Tools aus, welche zur Nutzung dieses Features zwingend installiert sein müssen. Bleiben diese aus, startet vSphere HA die VM aus. Beim Einschalten des Feature kann man zwischen „Nur VM Überwachung“ und „VM- und Anwendungsüberwachung“ wählen.
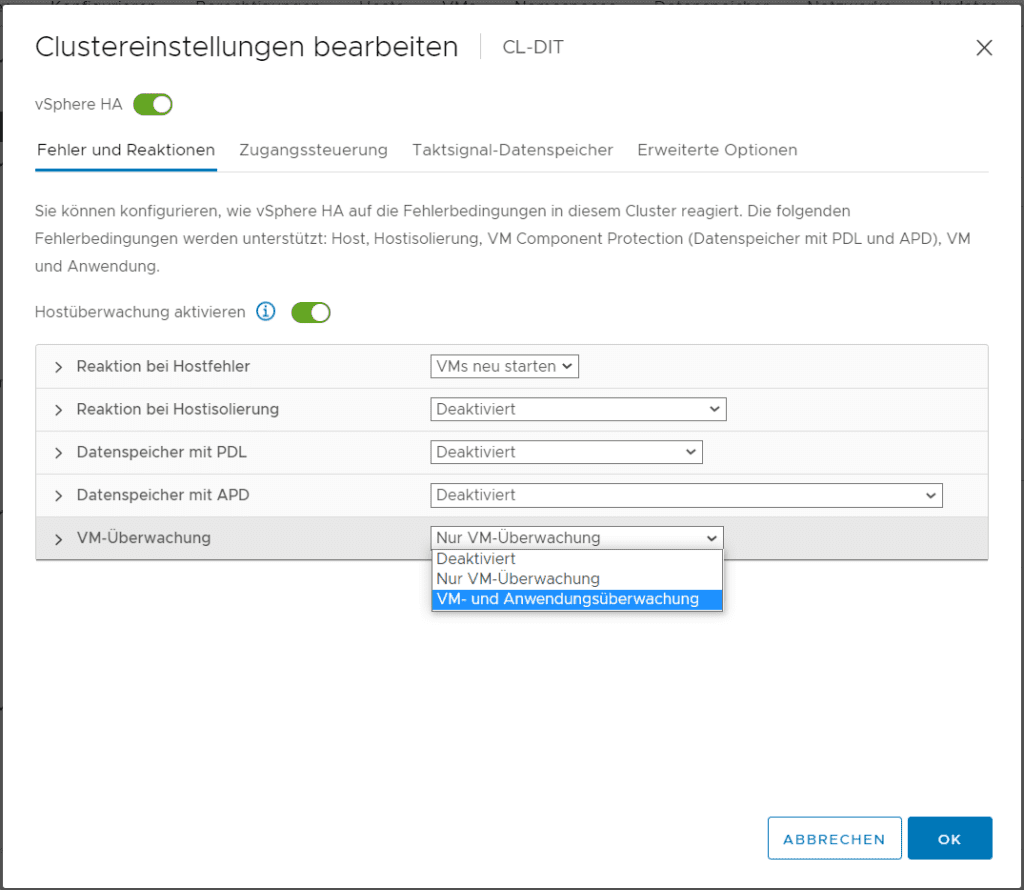
Letztes klingt erstmal interessant, kommt aber nur selten zum Einsatz. Hier die Erklärung: Aktiviert der Nutzer die VM-Überwachung, überprüft der VM-Überwachungsdienst mithilfe von VMware Tools auf Basis des regelmäßigen Eintreffens von Taktsignalen sowie der I/O-Aktivität des VMware Tools-Prozesses, der im Gastbetriebssystems läuft, ob die einzelnen virtuellen Maschinen im Cluster noch ausgeführt werden. Bleibt der Empfang von Taktsignale oder I/O-Aktivitäten aus, könnte das Gastbetriebssystem ausgefallen (Blue Screen) sein oder den VMware Tools konnte keine Rechenzeit zum Abschließen von Aufgaben zugeteilt werden. In einem solchen Fall diagnostiziert der VM-Überwachungsdienst den Ausfall der virtuellen Maschine und startet diese auf dem gleichen Host (der ja diesmal nicht ausgefallen ist) neu.
Virtuelle Maschinen oder Anwendungen können aber durchaus noch ordnungsgemäß ausgeführt werden, obwohl die Taktsignale ausbleiben. Um ein unnötiges Zurücksetzen zu vermeiden, überwacht der VM-Überwachungsdienst daher wie beschrieben zusätzlich die I/O-Aktivität einer virtuellen Maschine. Werden innerhalb des Fehlerintervalls keine Taktsignale empfangen werden, wird daher zusätzlich das I/O-Statistikintervall (ein Attribut auf Clusterebene) geprüft. Dieses bestimmt, ob während der vergangenen 2 Minuten von der virtuellen Maschine eine Festplatten- oder Netzwerkaktivität ausgegangen ist. Falls nicht, wird die virtuelle Maschine zurückgesetzt. Der Standardwert (120 Sekunden) lässt sich in den erweiterten Optionen mit dem Parameter
das.iostatsinterval
anpassen. Soweit so gut.
vSphere Guest SDK
Für die Anwendungsüberwachung braucht man hingegen eine Anwendung, die das vSphere HA Application Monitoring API unterstützt und in der Lage ist, entsprechende Taktsignale zu verarbeiten oder man muss selbst eine neue Anwendung programmieren, die sich auf das entsprechende SDK stützt, und dieses zum Einrichten von benutzerdefinierten Taktsignalen für die Anwendungen, die man überwachen möchte, verwenden. Das vSphere Guest SDK kann von VMware heruntergeladen werden.
Ist die Anwendung Dank SDK für die Anwendungsüberwachung „aware“, arbeitet das Feature ähnlich wie die VM-Überwachung. Wenn die Taktsignale für eine Anwendung nicht innerhalb einer angegebenen Frist empfangen werden, wird deren virtuelle Maschine neu gestartet.“
Summa summarum ist das Feature also erstmal nur sinnvoll, wenn man selbst eine neue Anwendung programmiert. Man kann aber die Überwachung im Gastbetriebssystem für Application HA z. B. auch mit vCenter Hyperic erweitern. Das Produkt wird aber seit 2020 nicht mehr von VMware verkauft, bzw. ist eingestellt. In diesem Fall kann/konnte mit Hilfe spezieller Agenten, die in jeder der überwachten VMs installiert sind, der Neustart der Anwendung ausgelöst werden.
Außerdem ist es theoretisch möglich, Anwendungen über vRealize LogInsight mithilfe des Microsoft Content Packs zu überwachen. Das kann Windows-VMs mit Hilfe kleiner, leichtgewichtiger Agenten überwachen. Das Content Pack bietet verwertbare Daten für Windows-Betriebsmanager, insbesondere zur Fehlerbehebung und Ermittlung von Problemen.
Kontakt

„*“ zeigt erforderliche Felder an

