Sichern von Azure-VMs in der Azure Cloud (Teil 1)

Backup-Grundlagen und Technologien
Du verfügst hoffentlich über ein Backup-Konzept für deine lokalen physischen oder virtuellen Server? Betreibst du außerdem nach und nach mehr Server auch in der Azure-Cloud, bietet es sich eventuell ein, deine Sicherungsstrategie zu überdenken, denn mit „Azure Backup & Site Recovery“ bietet Microsoft einen interessanten Service an, der gleichermaßen als Cloud-basierter Backup-Service sowie als kostengünstiges, skalierbares, hochverfügbares und sicheres Speicher-Backend in der Cloud dient. Erfahre mehr in unseren Microsoft Azure Schulungen.
Passende Schulungen
AZ-104 Microsoft Azure Administrator (AZ-104T00)
AZ-104 Microsoft Azure Administrator (AZ-104T00): Azure Administration für Profis

AZ-305 – Designing Microsoft Azure Infrastructure Solutions (AZ-305T00)
Gleich zu Anfang möchte ich ein paar Begrifflichkeiten einordnen. In diesem Artikel und den Folgenden geht es um den Dienst „Azure Backup and Site Recovery“, ein Plattform-Service von Microsoft, der Cloud-basierte Sicherungssoftware und Cloud-basierter Speicherdienst im einem ist.
Im Unterschied dazu könntest du aber auch im Azure-Portal im Marktplatz (Klick oben links auf „Ressource erstellen“) nach dem Begriff „Backup“ suchen und du wirst hunderte bekannte Sicherungslösungen finden, von denen die meisten auf Basis einer Azure-VM als Infrastruktur-Dienst laufen und als Speicherziel einen Azure-Storage-Account mit einem Blob-Container (Objekt-Speicher) nutzen.
Bei „Azure Backup und Site Recovery“ ist das nicht so, womit wir ein erstes entscheidendes Unterscheidungsmerkmal herausgearbeitet haben. Die mit dem Dienst „Azure Backup und Site Recovery“ korrespondierende Azure-Entität – der Sicherungstresor oder „Recovery Service Vaut“ (RSV) – ist sein eigener Speicherdienst.
Warum kein Speicherkonto?
Was spricht eigentlich gegen ein Speicherkonto als Speicherziel, zumal der Objektspeicherdienst (Blob) ja offensichtlich alle Anforderungen einer Backup-Lösung an Haltbarkeit (mit LRS liegt Diese bekanntlich bei 99,999999999, bzw. mit ZRS, GRS und GZRS noch höher), Verfügbarkeit, Skalierbarkeit, Zugriffssicherheit, Langzeitaufbewahrung sowie bei der Verschlüsselung in der Ruhe und bei der Übertragung und insbesondere auf der Kostenseite (Objektspeicher ist der mit Abstand preisgünstigste Speicherdienst) erfüllt? Zum einem ist das Speicherkonto ein universeller Speicherdienst, der neben Objektspeicher noch andere Speicherszenarien unterstützt, was die Gefahr birgt, dass du ihn absichtlich oder unabsichtlich noch für andere Dinge nutzt und zum anderen fallen bei einem Speicherkonto neben Kapazitätskosten und den Kosten für Transaktionen auch Kosten für die ausgehende Datenübertragung an. Je nachdem, wo du dann deine virtuelle Maschine mit der Sicherungslösung (Veeam, Commvault) betreibst (in Azure oder On Premise) und wie deine „Betriebs-Richtung“ (Backup oder Restore) gestaltet ist, schlägt die ausgehende Datenübertragung irgendwann merklich zu Buche.
Dies ist bei einem Recovery Service Vault nicht so, weil sämtliche Datenübertragungskosten hier stets inkludiert sind. Technisch gesehen ist aber ein Sicherungstresor (Recovery Service Vault oder Backup Vault (was seine Realisierung als Speicher-Backend angeht) auch nichts wesentlich anderes, als ein Speicherkonto, nur dass der Einsatzweck eben auf Backup begrenzt ist. Verschlüsselung, Authentifizierung, Langzeitaufbewahrung, Replikationsmodell usw. funktionieren hier genauso, ebenso wie Soft Delete und viele andere Funktionen, die du von einem Speicherkonto kennst.
Passende Schulungen
AZ-1002 – Konfigurieren des sicheren Zugriffs auf Ihre Workloads mithilfe virtueller Azure-Netzwerke
Backup Basics
Bevor wir aber den Dienst „Azure Backup und Site Recovery“ in Form eines „Sicherungstresors“ erstellen und nutzen, möchte ich dich an die wichtigsten Begriffe und Metriken im Bereich Backup und Replikation erinnern, denn in der Praxis wirst Du für jedes der drei Szenarien Backup, Replikation und Archivierung je eine eigenständige Software-Lösung brauchen, um alle Eventualitäten abzudecken. Daher beachte Folgendes:
- Trenne gedanklich BCDR (Business Continuity and Desaster Recovery) von Archivierung. Es gibt zwar Unternehmen, die missbrauchen eine Backup-Lösung für Archivierungszwecke – für viele Branchen ist die Archivierung, etwa in Form der E-Mail-Archivierung Pflicht -, doch dafür ist ein Backup-Programm nicht gedacht, denn …
- BC (in BCDR) steht für den unterbrechungsfreien IT-Betrieb, bzw. eine schnelle Wiederherstellung nach einer Unterbrechung, während …
- DR (in BCDR) die Notfallwiederherstellung nach Komponentenausfall oder Totalverlust meint.
- Demzufolge versteht man unter einem Backup eigentlich das Sichern eines Zustandes zu einem ganz bestimmten Zeitpunkt. Das Ziel dabei ist die Widerherstellung, etwa nach logischen Fehlern wie unbeabsichtigtem Löschen oder Virenbefall. Oft ist das Ziel auch nur die Aufbewahrung aufgrund regulatorischer Plichten. In diesem Fall dient das Backup also einem Archivierungszweck, auch wenn niemand ein 10 Jahre altes Backup wiederherstellen will.
- Replikation hingegen ist das fortwährende Spiegeln eines Systems an einen zweiten Betriebs- oder Aufbewahrungsstandorts zum Schutz vor Katastrophenszenarien. Aber Achtung: eine Replikationslösung repliziert immer auch logische Fehler an den zweiten Standort.
Alles zusammen genommen kannst du selbst bei einem gut geplanten Backup, das z. B. ein Mal pro Tag sichert, immer noch 23:59 Stunden an Daten verlieren. Bist du dazu bereit? Falls nein, kannst du natürlich 2 mal, 3 Mal oder 10 Mal am Tag sichern, allerdings wachsen damit auch Kosten und Aufwand.
Mit einer Replikationslösung wie Hyper-V-Replika hingegen kannst du den Zeitraum zwischen zwei Sicherungen optimal überbrücken, indem du ein Replikationsintervall von 15 Minuten, 5 Minuten oder im Idealfall 30 Sekunden konfigurierst. Die Replikationslösung in Azure (Azure Site Recovery), welche im Backend die gleiche Technologie verwendet, repliziert Daten konsistent von der Quellregion zur Notfallwiederherstellungsregion. Hierbei wird alle 5 Minuten ein absturzkonsistenter Wiederherstellungspunkt erstellt.
Sofern dir diese Zusammenhänge klar sind, kannst du auch die wichtigsten Metriken zur Bewertung von Backup-Lösungen und Backup-Performance besser einordnen. Verwende die folgenden Metriken, um zu bestimmen, wo du Redundanz hinzufügen musst, und um Vereinbarungen zum Servicelevel (SLAs) für Kunden festzulegen. Das Recovery Time Objective (RTO) ist die maximal akzeptable Zeit, die deine Anwendung nach einem Vorfall nicht verfügbar sein darf. Das Recovery Point Objective (RPO) ist die maximale Dauer des Datenverlusts, die während eines Notfalls akzeptabel ist, weil du ja durch das Widerherstellen eines Backups in der Zeit zurück gehst oder anderes ausgedrückt die Zeit, welche zwischen dem Zeitpunkt des Ausfalls bis zur vollständigen Wiederherstellung vergehen darf. Das betrifft nicht nur die Infrastruktur oder Daten sondern auch Prozesse und Aktivitäten.
Berücksichtige auch das Recovery Level Objective (RLO). Diese Metrik bestimmt die Granularität der Wiederherstellung. Musst du in der Lage sein, eine ganze Serverfarm, eine Webanwendung, eine Website oder nur ein bestimmtes Element wiederherzustellen.
Um diese Werte zu ermitteln, führst du im Idealfall eine Risikobeurteilung durch und stellst sicher, dass du die Kosten und Risiken von Ausfallzeiten oder Datenverlusten in deinem Unternehmen verstehst. Stelle dir dazu z. B. folgende Fragen: In welche Regionen möchtest du bereitstellen? Handelt es sich um gepaarte Regionen?
Muss deine DR-Lösung die gleichen Produktionsanforderungen erfüllen (z. B. gleicher/reduzierter Datenverkehr, geringere Leistung)?
Hier noch Mal die wichtigsten Metriken in der Zusammenfassung:
- RPO (Recovery Point Objective): der Zeitraum, den du maximal zu verlieren bereit bist und damit die Zeit, die höchstens zwischen 2 Sicherungen liegen darf.
- MTBF (Meantime beetween Failure) gibt an, wie lange eine Komponente vernünftigerweise zwischen Ausfällen durchhalten kann.
- MTTR (Repair, Recovery, Respond oder Resolve) ist die durchschnittliche Zeit, die benötigt wird, um eine Komponente nach einem Ausfall wiederherzustellen.
Sichern von virtuellen Maschinen
Nun noch ein paar Worte zum Sichern von virtuellen Maschinen an sich. Im Unterschied zu der Zeit, als Server und Clients noch auf physischem Blech liefen, handelt es sich bei virtuellen Maschinen – egal, ob unter Hyper-V, VMware, AWS oder Azure – ja bereits um Software, d. h. deren Festplatten sind nur Image-Dateien in einem Storage-System. Bei Azure werden diese sogenannten verwalteten Datenträger als Blobs in einem Azure-Storage-Account verwaltet. Sie bauchen beim Sichern von virtuellen Maschinen keinen Agenten für Ihre Backup-Software, welcher ohnehin nur in der Lage wäre, Datei&Ordner auf Betriebssystem-Ebene „abzuziehen“, was auch die Möglichkeiten einer Bare-Metal-Widerherstellung einschränkt. Bei einer virtuellen Maschine ist das viel einfacher, weil die Sicherungslösung die Sicherung direkt am Storage abziehen kann. Ist die VM ausgeschaltet genügt es, die Image-Dateien der VM-Datenträger „wegzukopieren“.
Selbstverständlich ist es in der Praxis viel interessanter, virtuelle Maschinen im laufenden Betrieb zu sichern. Dazu muss die Sicherungslösung neben den virtuellen Datenträgern (VHD/VHDX-Dateien bei Microsoft oder VMDK bei VMware) auch den Betriebszustand der virtuellen Maschine erfassen, indem sie den Inhalt des Arbeitsspeichers in einer Datei festhält, sowie den Zustand des Dateisystems. Außerdem muss sie sich um die Protokolle der Anwendungsebene kümmern, etwa bei einer SQL-Datenbank.
Alle großen Virtualisierungshersteller wie VMware oder Microsoft stellen zu diesem Zweck eine Data-Protection-API zur Verfügung, die von den führenden Backup-Herstellern wie z. B. Veeam auch unterstützt wird. VMware macht sich beim Sichern das hauseigene Snapshot-Verfahren zunutze, sodass z. B. Veeam einen VMware-Snapshot auslösen kann. Dieser „sperrt“ die Ursprungsfestplatte vor Schreibzugriffen, um diese problemlos sichern zu können und leitet temporäre Änderungen in eine Delta-Datei im (Redo-Log). Das Rede-Log wird nach Abschluss der Sicherung auf die Ursprungsdisk angewandt und der Snapshot schließlich von Veeam wieder aufgelöst.
Microsoft nutzt (bei Windows-VMs) ein ähnliches Verfahren, dass auf den Volume-Copy-Shadow-Services und einem entsprechenden VSS-Provider/Writer von Windows basiert. Um konsistente Schattenkopien von Daten oder Laufwerken im laufenden Betrieb anfertigen zu können, auch dann wenn einzelne Dateien geöffnet sind, koordiniert der Volume Shadow Copy Service die Aktionen verschiedener Komponenten. An so einem Volumeschattenkopie-Vorgang sind grundsätzlich die folgenden Komponenten beteiligt:
- der VSS-Systemdienst ist Bestandteil des Windows-Betriebssystems. Er koordiniert die Aktionen der weiteren Komponenten.
- der VSS-Requestor (Anforderer) fordert das Erzeugen einer Schattenkopie oder anderer Schattenkopie-Vorgänge an (zum Beispiel eine Sicherungs-Anwendung),
- der VSS-Writer (Schreiber) stellt sicher, dass ein konsistentes Dataset für eine Sicherung vorhanden ist (in der Regel als Teil einer „schattenkopiefähigen Anwendung“ wie MS-SQL-Server realisiert),
- der VSS-Provider (Anbieter) erstellt die Schattenkopie und verwaltet sie. Er kann sowohl als Hardware-basierter als auch Software-basierter Provider realisiert sein.
Die folgende Abbildung von Microsoft verdeutlicht die Zusammenhänge:
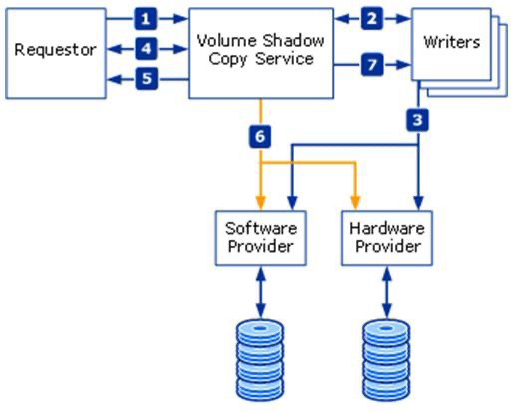
Um mit dem Volume Shadow Copy Service zu arbeiten, stellt das Windows-Betriebssystem verschiedene Tools zur Verfügung. Dazu zählen z. B. DiskShadow (für Windows-Server-Betriebssysteme) und VssAdmin. Bei DiskShadow handelt es sich um einen Requestor, mit dem sich Schattenkopien des Server-Systems erstellen und verwalten lassen.
Ebenfalls zu den unterstützten Funktionen einer Data-Protection-API gehört – sowohl bei VMware, als auch bei Microsoft – der Support für das „Changed-Block-Tracking“-Protokoll (CBT). Der Name stammt eigentlich von VMware; Microsoft setzt in Azure und Hyper-V nur eine vergleichbare Technologie ein. Diese verfolgt die Änderungen einer virtuellen Maschine auf Block-Level und markiert (seit der letzten Sicherung) veränderte Blöcke. Die Technologie wird vorrangig zur Durchführung inkrementelle Backups eingesetzt. Inkrementelle Backups beschleunigen die Datensicherung und reduzieren die zu speichernde Datenmenge. CBT ist über eine API von externen Backup-Lösungen nutzbar.
Schauen wir uns im nächsten Teil dieses Beitrages an, wenn das Zusammenspiel der einzelnen Komponenten eines Backup-Vorgangs funktioniert, wenn Sie Azure-VMs in einen Recovery-Service-Vault sichern. Weitere Folgen dieser kleinen Beitragsserie befassen sich mit dem Sichern von Azure-Dateifreigaben, dem Sichern von Dateien&Ordnern auf OS-Ebene, sowie dem Sichern von lokalen Windows/Linux-VMs mit dem Azure Backup Server. Der letzte Teil befasst sich dann mit dem Thema Azure Site Recovery als Cloud-basierte Replikationslösung.
Kontakt

„*“ zeigt erforderliche Felder an

