Azure Batch in der Praxis
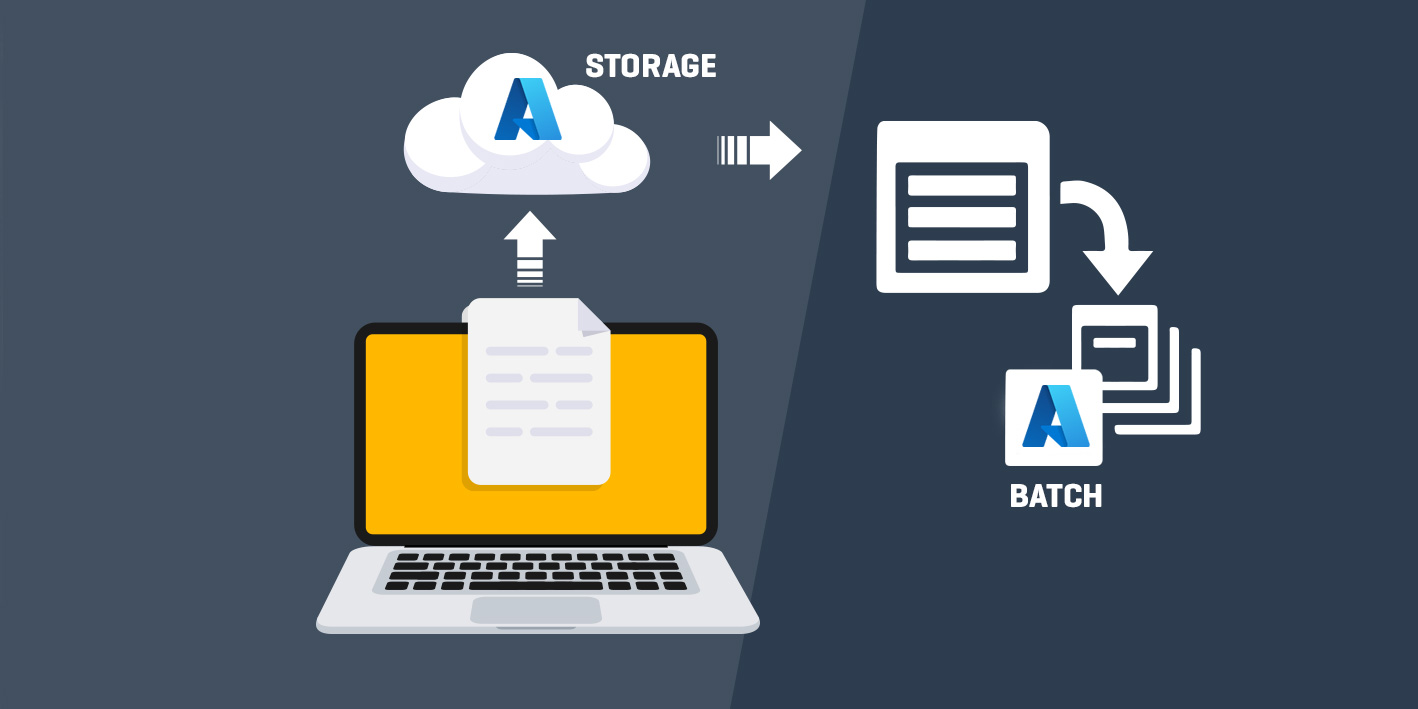
OCR im Eigenbau mit Azure Batch und Azure Functions
Mit Azure Batch steht Entwicklern in Azure eine Plattform zur Verfügung, auf der sie unter anderem umfangreiche, auf Parallelverarbeitung ausgelegte HPC-Batchaufträge (High Performance Computing) in Azure ausführen können. So können Entwickler beispielsweise SaaS-Anwendungen oder Client-Apps erstellen, für die große Mengen von Ausführungen benötigt werden.
Passende Schulungen
AZ-204 Developing Solutions for Microsoft Azure (AZ-204T00)

AI-102 – Designing and Implementing a Microsoft Azure AI Solution (AI-102T00)
Du benötigst mehr Know-how rund um MS Azure? Dann empfehlen wir dir unsere Microsoft Azure Schulungen!
Vom Prinzip her gestaltet sich die Arbeitsweise mit dem Plattform-Dienst so, dass Azure Batch vollkommen automatisch einen Pool mit Compute-Knoten (VMs) bereitstellt, dort die gewünschten Anwendungen installiert und schließlich deren Ausführung als Aufträge auf den Compute-Knoten einplant.
Prominente Beispiele für den Einsatz von Batch-Processing sind Monte-Carlo-Risikosimulationen, welche häufig von Finanzdienstleistungsunternehmen eingesetzt werden oder allgemein das Erstellen von Diensten zur Verarbeitung großen Mengen von Bildern. Auch für so genannte eng gekoppelte Workloads wie FE-Analyse, Strömungssimulation oder das KI-Training mit mehreren Knoten eignet sich Azure Batch gut. Darüber hinaus unterstützt Azure Batch größere Mengen von Rendering-Workloads mit Rendering-Tools wie beispielsweise Autodesk Maya, 3ds Max oder V-Ray.
Haupteinsatzzweck ist aber sicher die Ausführung intrinsisch paralleler Workloads, also Anwendungen, die einerseits unabhängig voneinander ausgeführt werden, bei denen aber jede Instanz nur einen Teil der Arbeit erledigt. Beliebte Beispiele für intrinsisch parallele Workloads, die sich mit Azure Batch ausführen lassen, sind neben der bereits erwähnten Bildanalyse und -verarbeitung und der Modellierung von Finanzrisiken mit Monte Carlo-Simulationen, Medientranscodierung, die Datenerfassung-/Verarbeitung im Rahmen von ETL-Vorgängen, die Analyse genetischer Sequenzen, das Ausführen von Softwaretest oder die optische Zeichenerkennung (OCR). Letzte eignet sich im Rahmen dieses Beitrags gut für eine kurze Demo.
Grundlegende Konzepte von Azure Batch
Um erste Workloads mir Azure Batch erstellen zu können, brauchst du ein grundlegendes Verständnis der beteiligen Konzepte Batch Konto, Knoten und Pools sowie Aufträgen und Aufgaben. Zunächst musst du ein Azure Batch-Konto anlegen. Darunter versteht Microsoft eine eindeutig identifizierbare Entität innerhalb des Batch-Diensts. Da die meisten Batch-Lösungen Azure Storage zur Speicherung von Ressourcen- und Ausgabedateien nutzen, ist jedem Azure Batch-Konto in der Regel ein entsprechenden Speicherkonto zugeordnet. Die Zuordnung kannst du beim Anlegen des Batch-Account vornehmen. Du kannst ein Batch-Konto pro Region anlegen.
Passende Schulungen
AZ-400 – Microsoft Azure DevOps Engineer (AZ-400T00)
AZ-400 - Microsoft Azure DevOps Engineer - Der Kurs bereitet dich auf die DevOps Zertifizierung AZ-400 vor.
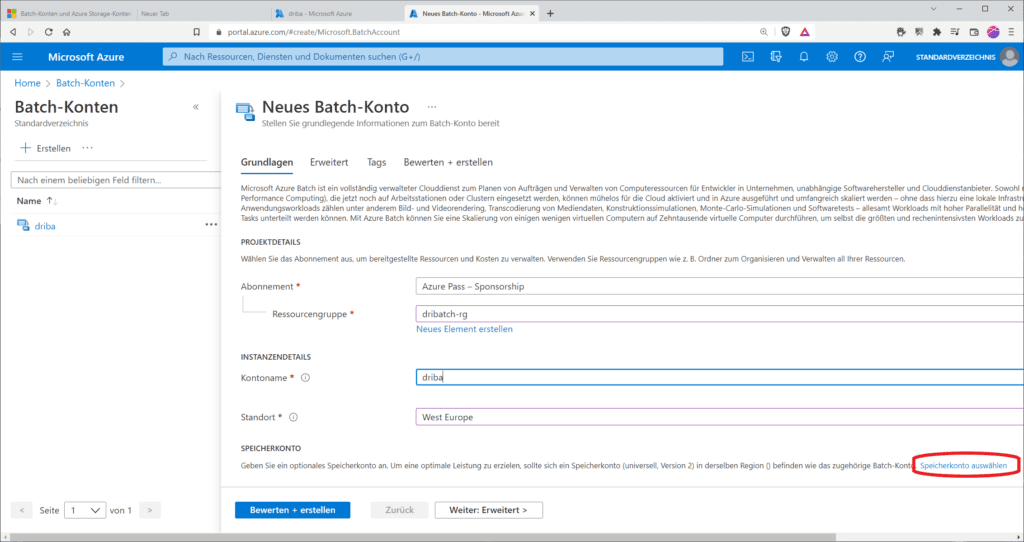
Wurde das Batch-Konto erstellt, kannst du darin Pools und Knoten erstellen. Dies erledigst du im Batch-Konto im Abschnitt „Features / Pools“
Prinzipiell lassen sich mehrere Batch-Workloads in einem einzelnen Batch-Konto ausführen, aber falls gewünscht auch auf mehrere Batch-Konten verteilen, sofern sich diese im gleichen Abonnement, aber in verschiedenen Azure-Regionen, befinden.
Pools
Erstelle nun einen neuen Pool mit dem Namen „ocr-pool“, wähle bei „Imagetyp“ den Eintrag „Marketplace“ und als „Herausgeber“ den Eintrag „canonical“. Optional stehen als Images „debian“, „microsoftwindowsserver“ oder „microsoft-azure-batch“ zur Verfügung, aber für dieses Beispiel benötigen wir ein einfaches „Linux“-System. Als „Angebot“ nutzen wir daher „ubuntuserver“ und als SKU „18.04-lts“.
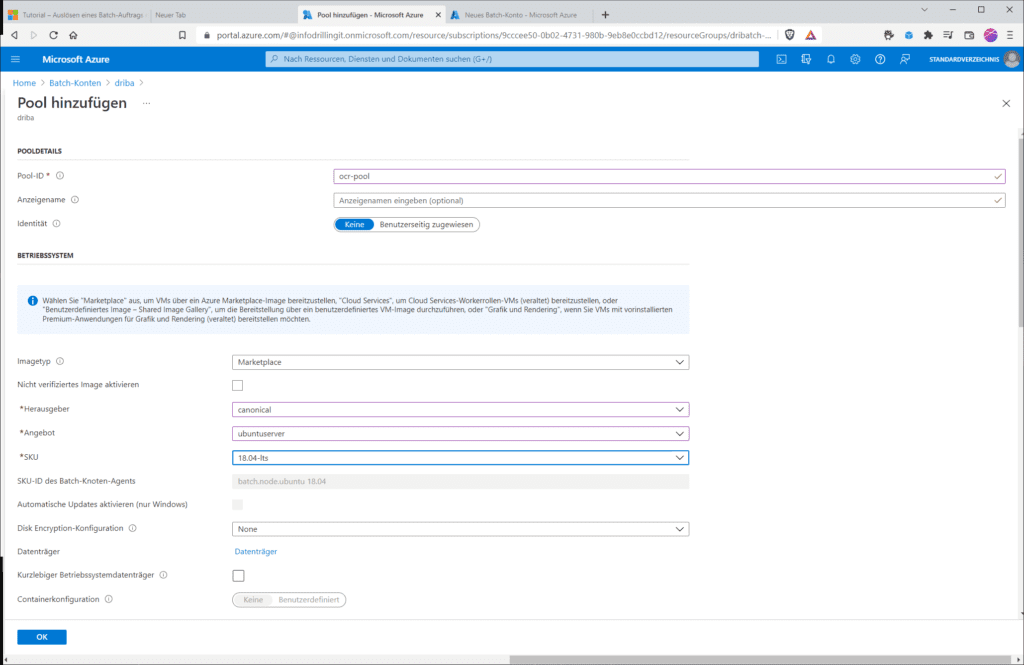
Im Abschnitt „Knotengröße“ legst du zunächst die gewünschte VM-Größe fest. Dies verhält sich ähnlich wie beim Azure Kubernetes Service (AKS). Es handelt sich zwar im Prinzip um normale Azure-VMs, diese tauchen aber ausschließlich im Kontext von Azure Batch auf“. Im Normalfall empfiehlt sich bei Batch-Workloads ein Hardware-Typ, der besonders für HPC-Workloads geeignet ist, etwa ein System aus der F-Serie wie z. B. „Standard_f2s_v2“. Für unser einfaches Beispiel genügt aber auch ein System aus der A-, B- oder D-Serie für Allzweck-Workloads. Verantwortlich für die letztlich erzielbare Performance ist nicht nur die Anzahl Kerne der gewählten Compute-Hardware, sondern auch die Anzahl der Konten im Pool. Dabei kannst du zwischen einer festen Größe des Pools und Autoscaling wählen: Wenn du auf eine festen Knotenzahl setzt, sind sicherlich 3 Knoten ein vernünftiger Ausgangspunkt; aus Kostengründen kannst du für das Nachvollziehen dieser Demo auch mit einem Knoten starten.
Entscheidend für unser Beispiel ist aber, dass du im Abschnitt „Starttask“ einen Startsequenz angibst, die auf jedem einzelnen Compute-Knoten ausgeführt wird, sobald dieser dem Pool hinzugefügt oder wenn der Knoten neu gestartet wird. Da wir es hier mit Linux-Instanzen zu tun haben, verwendest du für dieses Beispiel folgendes BASH-Skript als Starttask:
/bin/bash -c
"sudo update-locale LC_ALL=C.UTF-8 LANG=C.UTF-8; sudo apt-get update; sudo apt-get -y install ocrmypdf"
An der Installation des Linux-Paketes „ocrmypdf“ kannst du erahnen, dass unsere später zu verwendende Azure-Function, die beim Upload eines scanntes Dokumentes in ein Speicherkonto, eine OCR-Vorgang anstoßen soll, das populäre OpenSource-Tool verwenden wird.
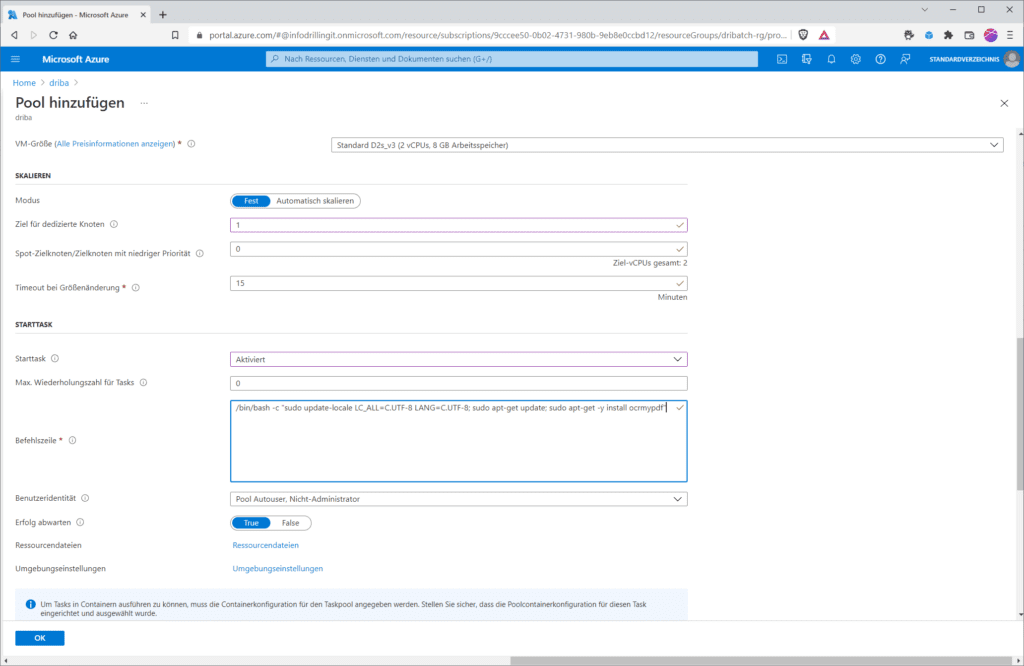
Alle übrigen Einstellungen kannst du für dieses Beispiel auf den Default-Werten belassen. Wurde der Pool erstellt, wird er mitsamt der zugewiesenen dedizierten Knotenzahl im Abschnitt „Pools“ des Batch-Accounts angezeigt.
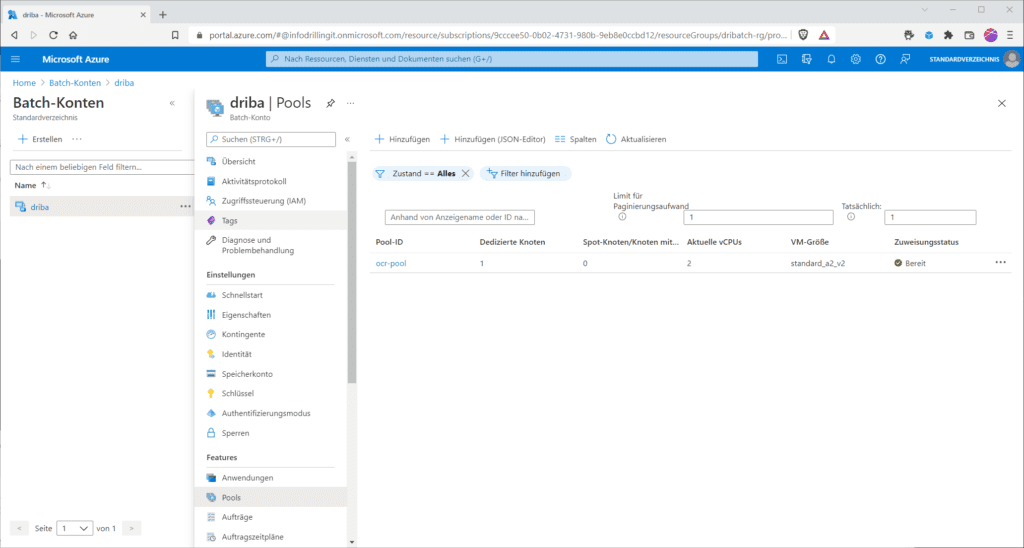
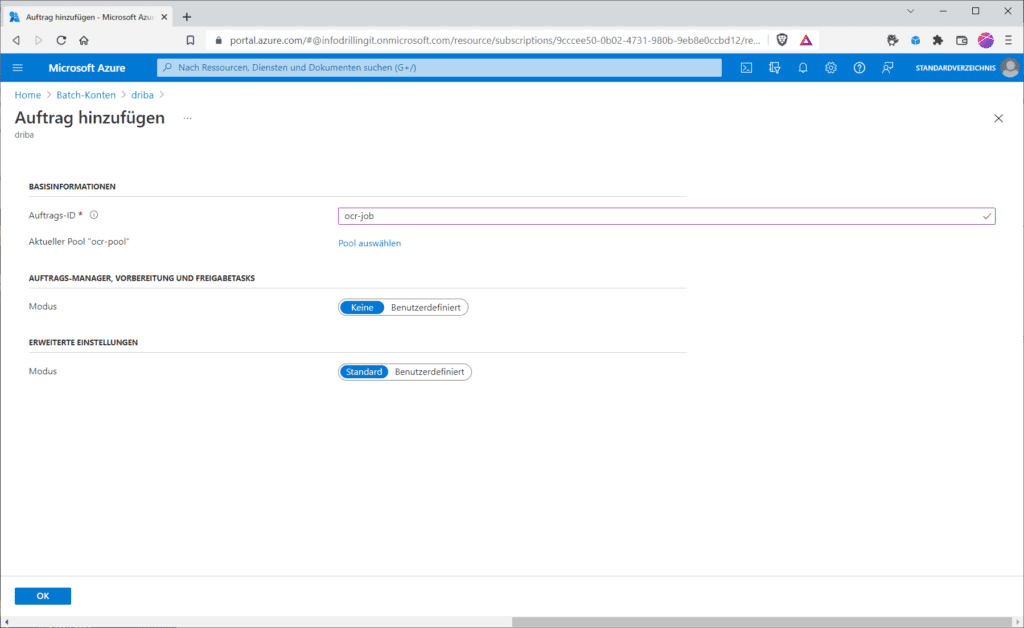
Ist das erledigt, kannst du im Abschnitt „Features / Aufträge“ einen Auftrag erstellen. Der benötigt erst einmal nur eine Auftrags-ID, z. B. „ocr-job“. Außerdem musst du den zu verwendenden Pool auswählen.
Speicherkonten und Azure Functions
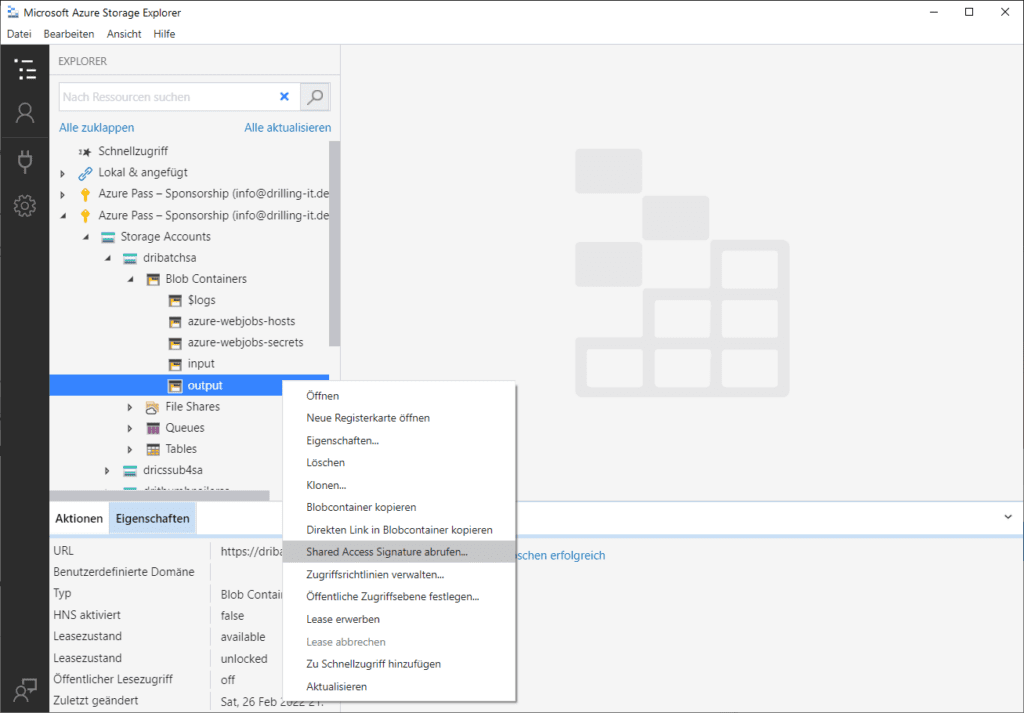
Jetzt wechsel in das mit dem Batch-Account verknüpfte Speicherkonto und erstelle zwei Blob-Container mit dem Namen „input“ und „output“. Der Container „input“ dient dem Upload gescannter Dokumente und damit als Ereignis-Trigger für eine Azure-Function, die dann den ocr-Batch auslöst, während „output“ als Ziel-Container für die per ORC analysierten Dokumente dient. Wie man Container erstellt, haben wie dir schon in verschiedenen Artikel gezeigt. Für den sicheren anonymen Schreibzugriff auf den Ziel-Container „output“ erzeugst du noch eine SAS (Shared Access Signature), also eine signierte URL. Dies gelingt am einfachsten im https://azure.microsoft.com/en-us/features/storage-explorer/ Azure Storage Explorer. Durch einen Rechtsklick auf den gewünschten Container kannst du dann einfach den Eintrag „Shared Access Signature abrufen“ nutzen.
Du benötigst die Berechtigung „Schreiben“ und einen gewünschten Bereich für die Dauer der SAS-Gültigkeit.
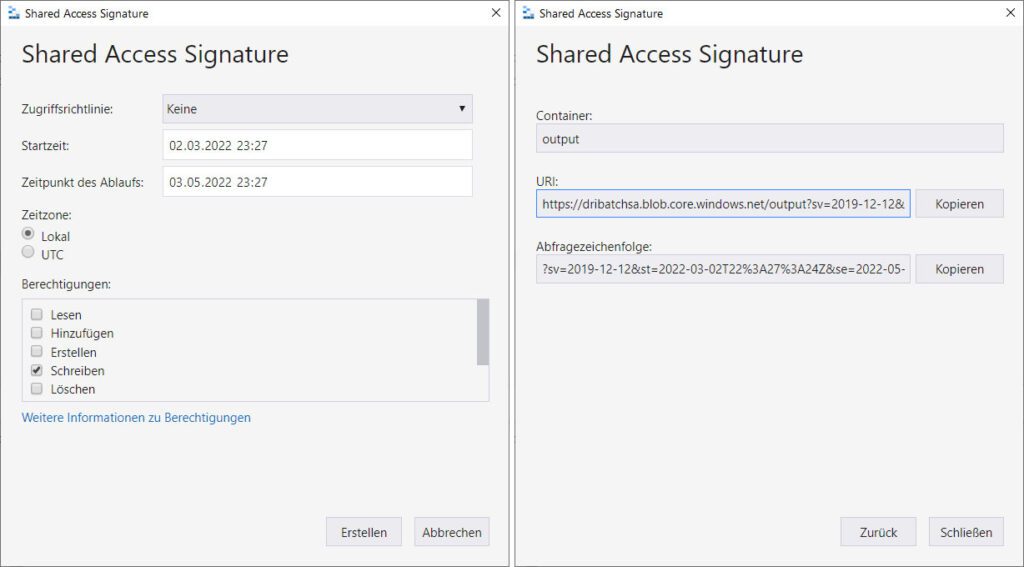
Wurde die SAS abgerufen, kopiere SAS-URL und Abfragezeichenfolge in die Zwischenablage, da du diese später zum Autorisieren der Azure-Function benötigst.
Danach erstelle im Azure-Portal eine neue Azure Function (Function App) mit serverlosen Verbrauchsplan. Wie das geht, haben wie bereits in verschiedenen Artikeln demonstriert. Verwende diesmal .NET als Laufzeitstapel. Die für dieses Beispiel verwendete Function ist in C# geschrieben, um das Azure-Batch .NET SDK nutzen zu können. Wenn du den serverlosen Verbrauchsplan gewählt hast musst du im Abschnitt „Hosting“ des Bereitstellungsassistenten das Speicherkonto angeben, das du oben erstellst und welches du mit der Azure Function verknüpfen möchtest.
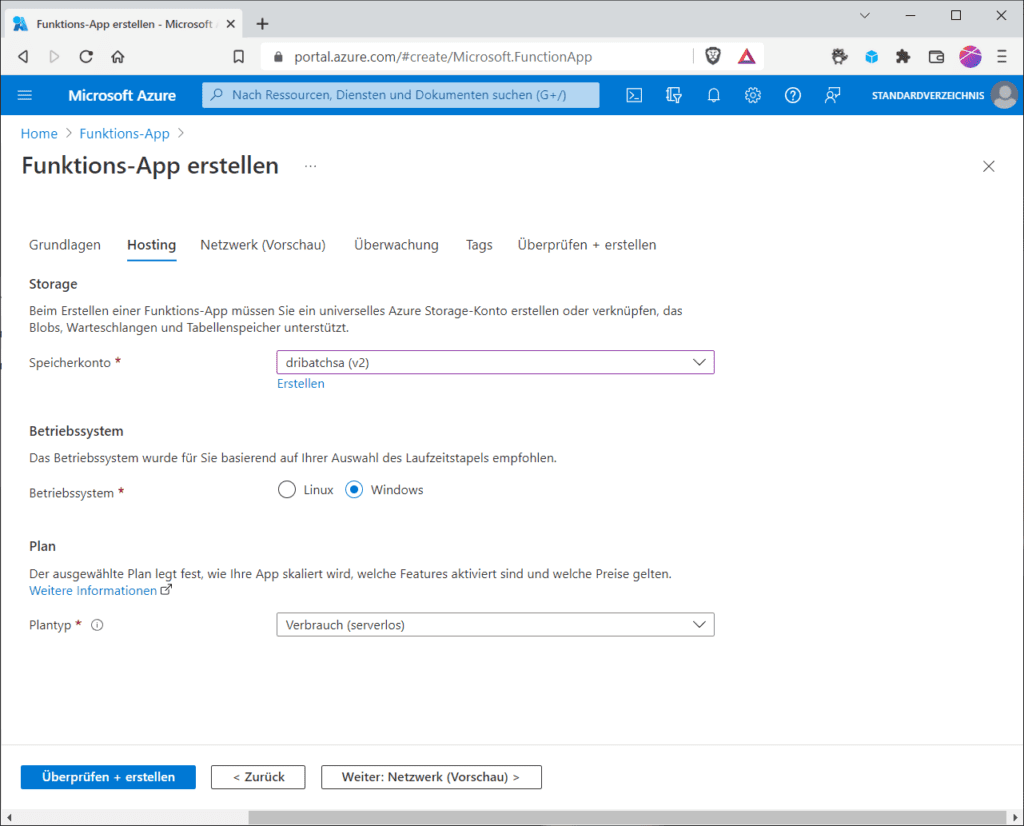
Wurde die Function-App erstellt, musst du noch im Abschnitt „Funktionen“ einen neuen Trigger für Blob-Speicherkonten erstellen. Wähle bei „Entwicklungseinstellungen“ den Eintrag „im Portal entwickeln“. Im Abschnitt „Vorlagendetails“ wähle bei „neue Funktion“ einen beliebigen Namen für deinen Trigger, und bei „Pfad“ ersetze im Vorschlag „samples-workitems/{name}“ dem Eintrag „samples-workitems“ durch den Namen deines Eingangs-Containers, in unserem Beispiel „input“. Bei „Speicherkontoverbindung“ handelt es sich um den Namen der App-Einstellung, welche dann die Verbindungszeichenfolge für dein Speicherkonto enthält. Hier ist der Eintrag „AzureWebJobsStorage“ korrekt.
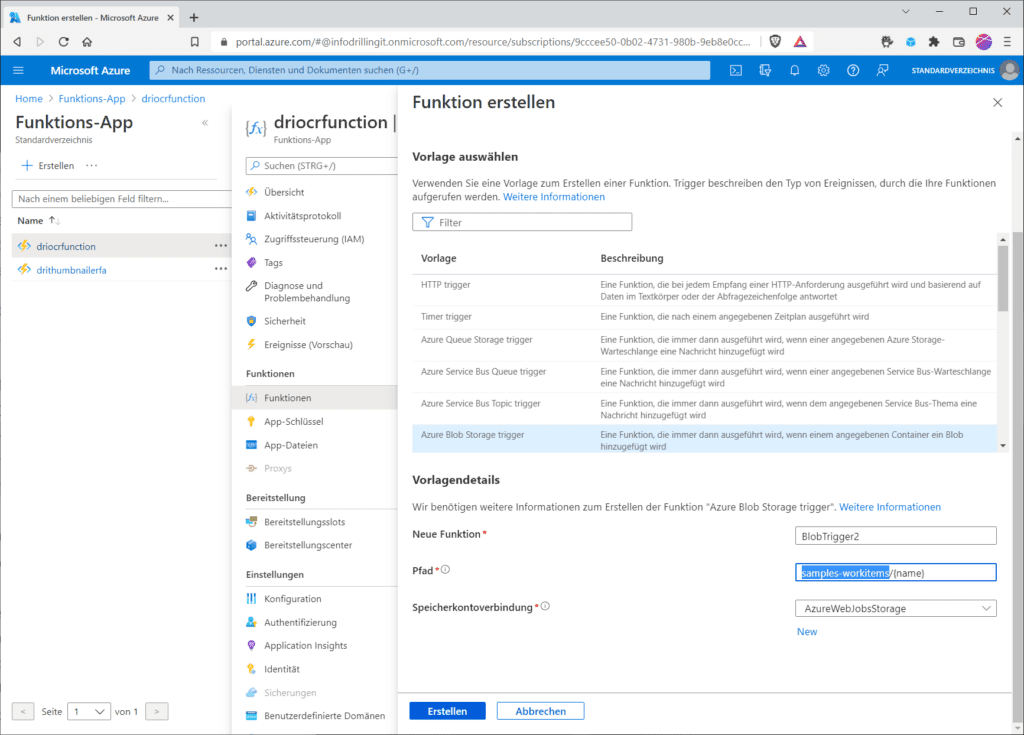
Hast du den Trigger erstellt, kannst du den eigentlichen Funktionscode einfügen. Wähle dazu im Abschnitt „Funktionen“ den Eintrag „Funktionen“ und klicke dort auf den Link mit dem Namen deines Blob-Triggers. Klicke dann auf „Programmieren und testen“ und lade durch einen weiteren Klick auf „Hochladen“ oder mittels Copy&Paste deinen Funktionscode in die Datei „run.csx“ hoch. Den Demo-Code für diese Anwendung stellt Microsoft auf https://github.com/Azure-Samples/batch-functions-tutorial/blob/master/run.csx Github zur Verfügung. Außerdem benötigst du noch eine Projekt-Datei. Auch deren Content ist auf https://github.com/Azure-Samples/batch-functions-tutorial/blob/master/function.proj Github zu finden, allerdings ist die Datei „function.proj“ im Azure-Portal standardmäßig nicht vorhanden, so dass du diese erst anlegen musst. Dort sind die externen Bibliotheken im Funktionscode, wie z. B. das Batch .NET SDK referenziert.
Schließlich musst du nur noch in der „run.csx“ die Platzhalter in der Funktion „Run()“ in der Zeile 25 …
BatchSharedKeyCredentials cred = new BatchSharedKeyCredentials("<YOUR_BATCH_URL_HERE>", "<YOUR_BATCH_ACCOUNT_HERE>", "<YOUR_BATCH_PRIMARY_KEY_HERE>");
… mit deinen Werten ersetzen. Das betrifft die „BatchSharedKeyCredentials”, welche sich aus der „Batch-URL“, der „Batch-Account-ID“ und dem „primären Batch-Account-Schlüssel“ zusammensetzen.
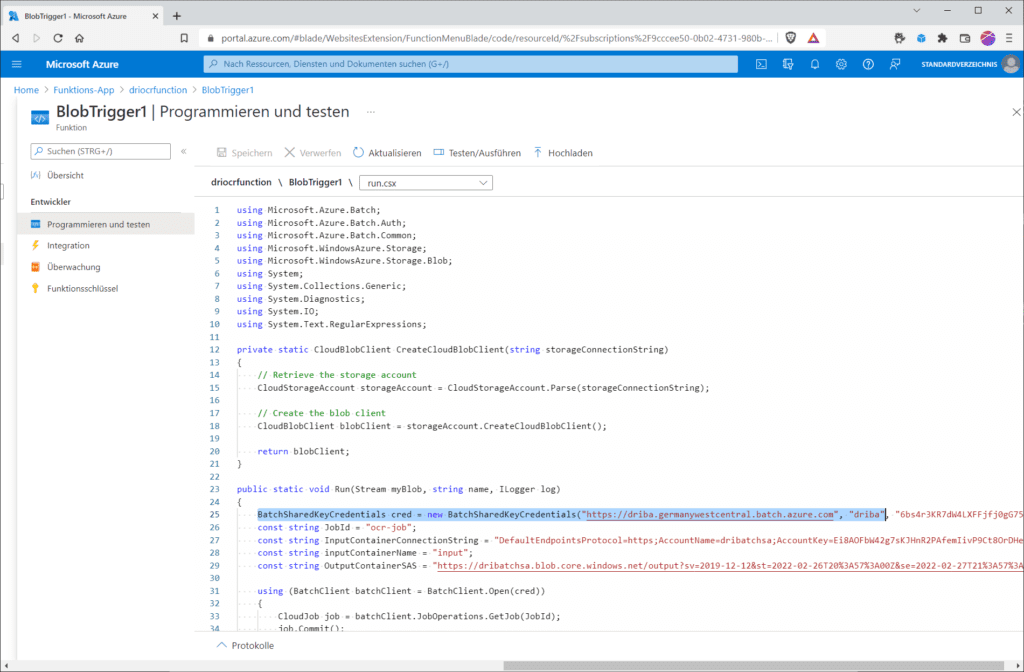
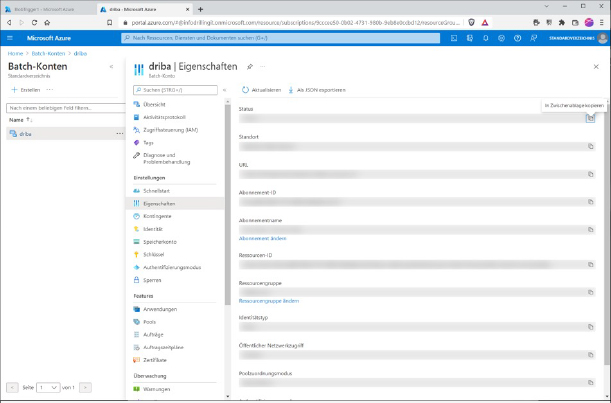
Du findest die Informationen in deinem Batch-Account unter „Eigenschaften“.
Außerdem musst du in den folgenden Zeilen 27,28 und 29 noch deine Speicherkonto-Verbindungszeichenfolge, den Namen deines Eingangs-Containers und die oben anlegte SAS für den Ausgabe-Container („output“) ergänzen.
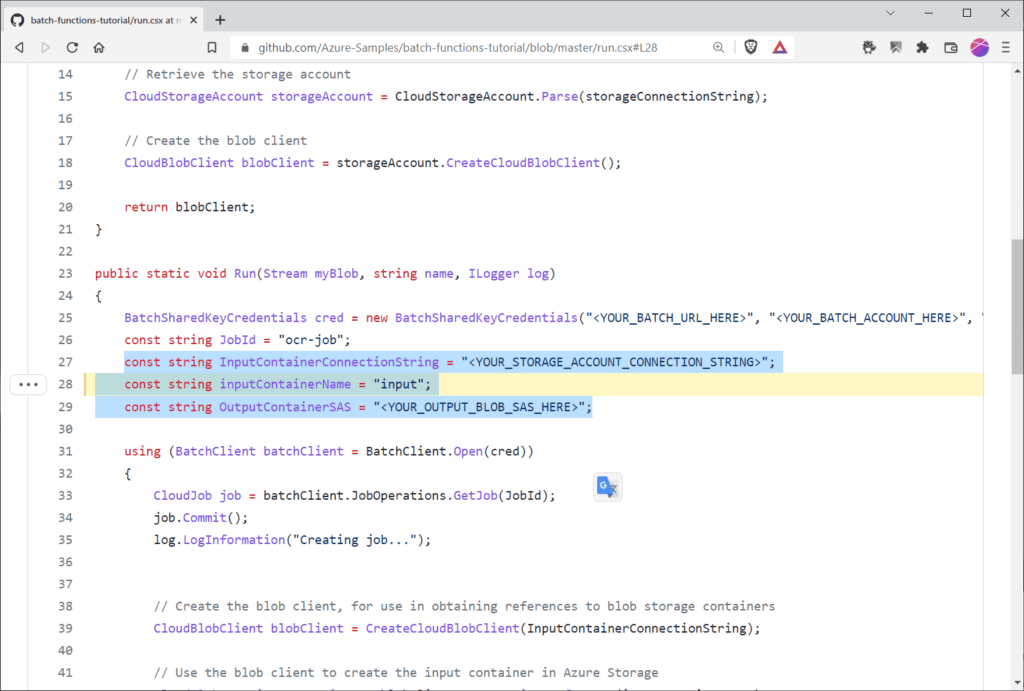
Achtung: Bei “SAS” handelt es sich um die SAS-URL, nicht nur das Token.
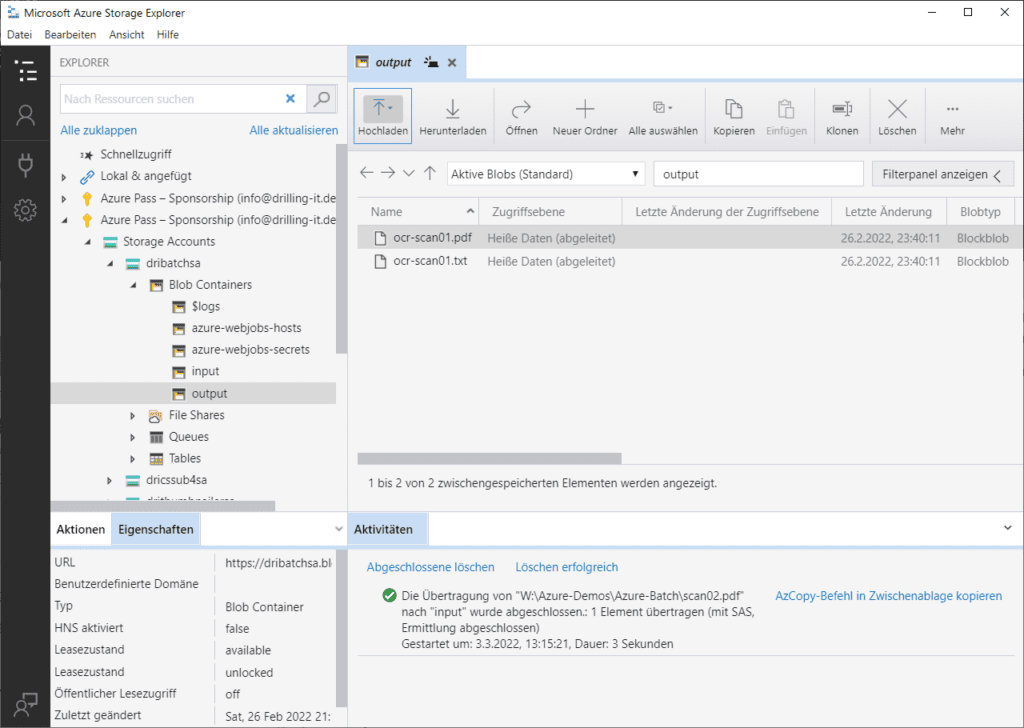
Ist alles erledigt, kannst du ein gescanntes Dokument in den Container „input“ hochladen und findest nach wenigen Sekunden das dekodierte Dokument im Container „output“.
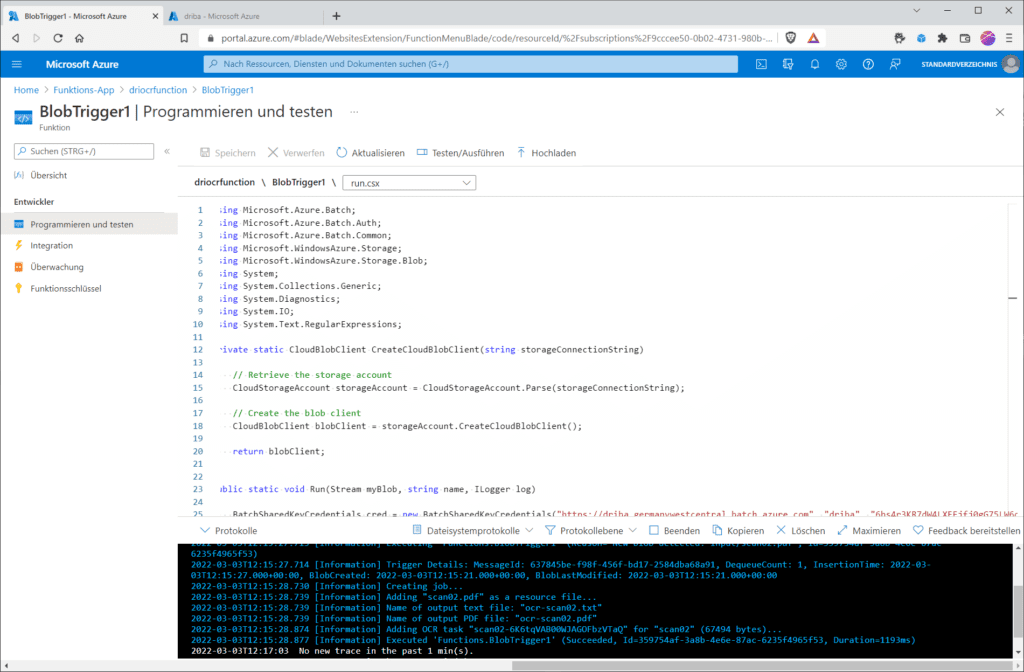
Dass die Azure-Function erfolgreich gelaufen ist, siehst du in der Azure-Function selbst unter „Protokolle“ …
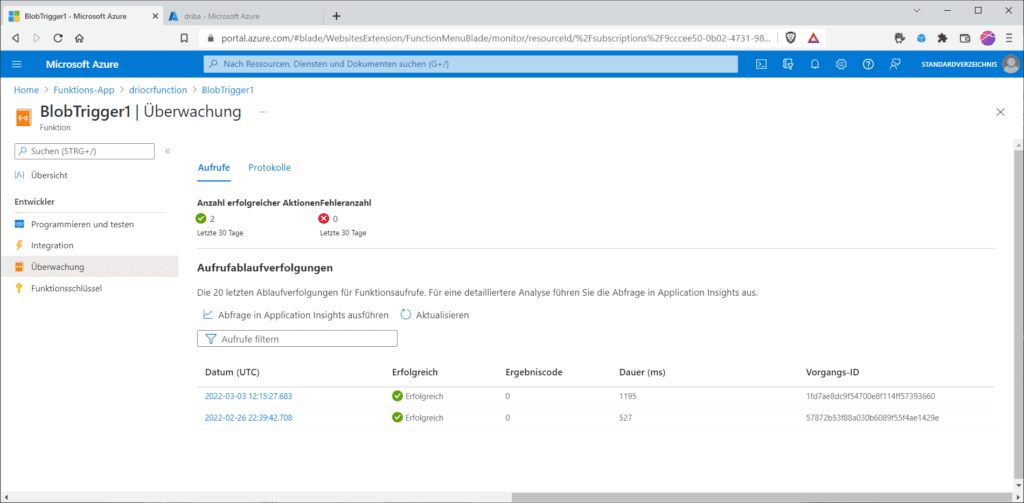
… sowie in der Azure-Function im Blob-Trigger im Abschnitt „Überwachung“ …
Dass der Batch selbst erfolgreich gelaufen ist, siehst du dagegen im Batch-Account unter „Aufträge / ocr-job“ …
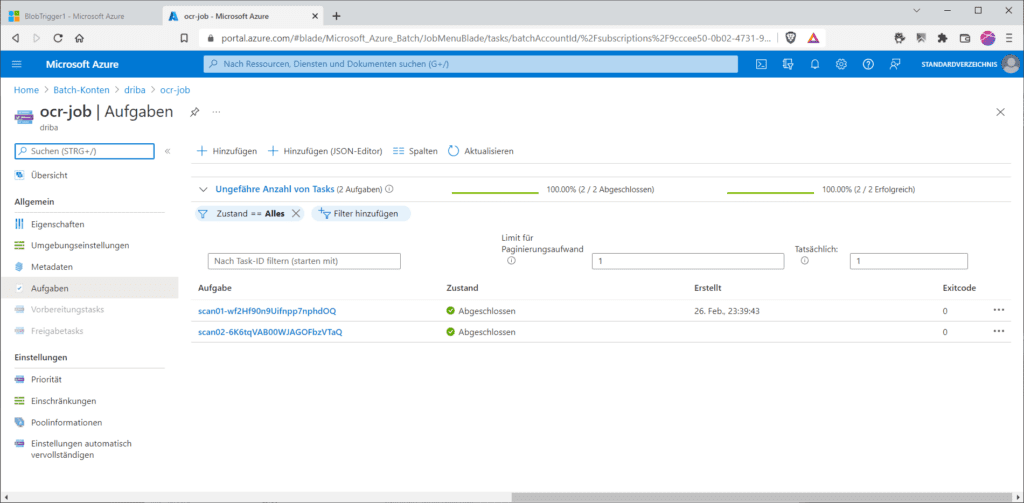
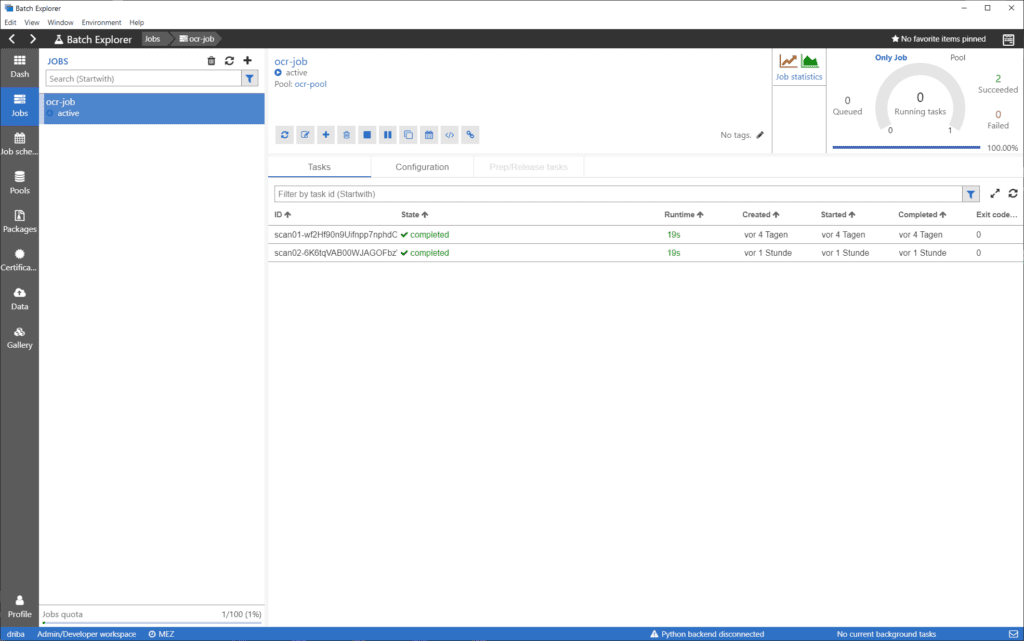
… oder im Azure-Batch-Explorer, den du dir von Microsoft für Windows, Linux oder Mac https://azure.github.io/BatchExplorer/ herunterladen kannst.
Kontakt

„*“ zeigt erforderliche Felder an

