Sicherheit und Azure – eine coole GeSchichte
Sicherheit und Azure – Schicht 1: Sicherheit der physischen Infrastruktur
Die mit Abstand häufigsten Fragen der Teilnehmer in unseren Azure-Kursen – insbesondere bei den einführenden Seminaren – bezieht sich auf Sicherheit. Im Detail fragen sich Teilnehmer, wie es um die Sicherheit integrierter Server und Anwendungen sowie um Sicherheit von Unternehmens- und Kundendaten bestellt ist. Da Sicherheit in der Cloud einem mehrschichtigen Ansatz folgt und zudem je nach Service-Modell (IaaS, PaaS, SaaS) unterschiedliche Verantwortlichkeiten umfasst – insbesondere bei IaaS hat auch der Kunde seinen Teil beizutragen – möchten wir das Thema in einer Artikelserie in allen Facetten beleuchten. Der Fokus liegt dabei allerdings diesmal bei konzeptionellen Betrachtungen, nicht so sehr in Anleitungen zur technischen Umsetzung.
Passende Schulungen
AZ-104 Microsoft Azure Administrator (AZ-104T00)
AZ-104 Microsoft Azure Administrator (AZ-104T00): Azure Administration für Profis

AZ-305 – Designing Microsoft Azure Infrastructure Solutions (AZ-305T00)
Das sichere Betreiben von Anwendungen in der Cloud basiert auf einem mehrstufigen Sicherheitsansatz, der die Schichten Physische Sicherheit, Identitäten und Zugriff, Umkreisnetzwerk, virtuelles Netzwerk, Anwendungen und Daten umfasst, wie die folgende Abbildung demonstriert:
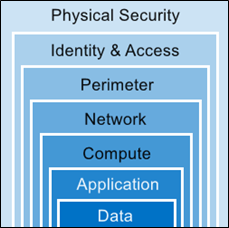
In diesem Zusammenhang spielt das Modell der gemeinsamen Verantwortung (Shares Responsibility) eine entscheidende Rolle. Während du in deinem lokalen Rechenzentrum stets für den gesamten Sicherheitsstack selbst zuständig bist, wird bei einer Migration in die Cloud ein Teil der Zuständigkeit auf Microsoft übertragen, abhängig vom Service-Modell (SaaS, Paas, IaaS).

Während im lokalen Rechenzentrum viele Sicherheitsverantwortlichkeiten wegen begrenzter Ressourcen gar nicht erfüllt sind, kannst du beim cloudbasierten Sicherheitsmodell deutlich mehr der täglichen Sicherheitsaufgaben an Microsoft übertragen. Außerdem ist es möglich zusätzliche cloudbasierte Sicherheitsfunktionen einzusetzen oder von Cloud Intelligence zur Verbesserung der Bedrohungserkennung profitieren. Aus der Perspektive des Betreibers kümmert sich Microsoft also um die Bereiche „Physische Sicherheit“, „Verfügbarkeit“, „Komponenten“, Netzwerkarchitektur“, „das eigene Produktionsnetzwerk“, die vielen Azure-Sevices zugrunde liegende SQL-Datenbank, um sämtliche „Vorgänge“ auf der Azure-Plattform, sowie um das Überwachen und die Integrität des Stacks. In diesem ersten Teil werfen wir nun einen Blick auf die „physische“ Sicherheit und beleuchten zu diesem Zweck die Infrastruktur der Microsoft-Rechenzentren:
Sicherheit und Azure: Infrastruktur der Rechenzentren
Die Azure-Cloud basiert auf global verteilten Rechenzentrumsinfrastruktur, die Tausende von Online-Diensten unterstützt. Laut Microsoft befindet sich diese Infrastruktur physisch in weltweit mehr als 100 extrem sicheren „Einrichtungen“, die sich auf mehr als 60 Regionen weltweit und auf 140 Länder verteilen. Die Liste der verfügbaren Regionen kannst du jederzeit https://azure.microsoft.com/regions/ online abrufen, aber auch durch einen simplen Azure Powershell-Aufruf „Get-AzLocation“. Dieser liefert Meta-Daten zu allen Standorten einschließlich der zugehörigen Google-Koordinaten. Benötigst du nur die zugehörigen Region-Codes, verwende:
(Get-AzLocation).Location
Passende Schulungen
AZ-500 – Microsoft Azure Security Technologies (AZ-500T00)
AZ-500 – Microsoft Azure Security Technologies (AZ-500T00): Kenntnisse zur Sicherung von Microsoft Azure-Umgebungen
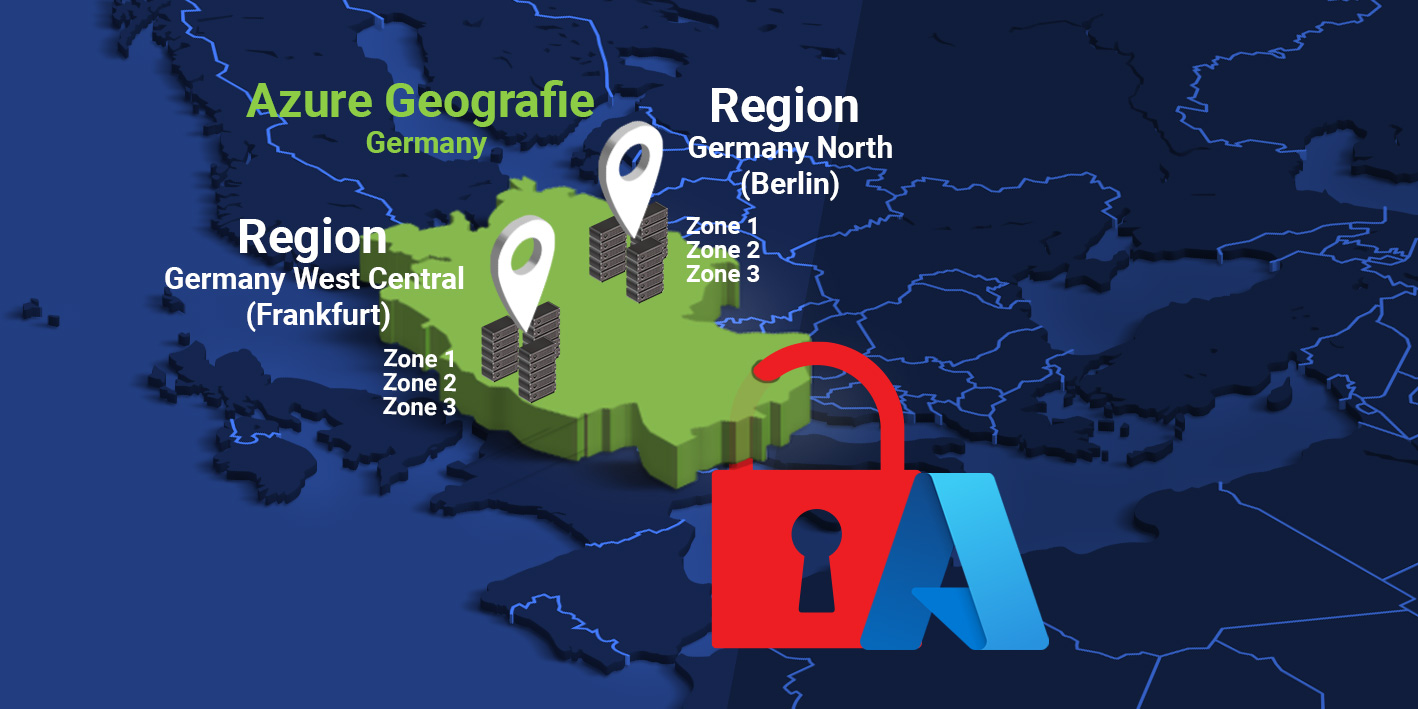
Jede Region besteht aus mindestens einem, in der Regel aber aus mehreren Rechenzentren zur Bereitstellung von Redundanz und Verfügbarkeit. Jede Region ist von jeder anderen vollständig unabhängig und verfügt jeweils über eigene Strom-, Netzwerk- Versorgung und Kühlung. Azure-Regionen gruppieren sich jeweils zu so genannten „Geografien“, um Anforderungen an Datenresidenz, Datenhoheit, Compliance und Ausfallsicherheit innerhalb geografischer Grenzen zu erfüllen, denn eine Azure Geografie umfasst nur Regionen aus dem gleichen „geopolitischen Raum“. Für deutsche Nutzer sind z. B. die Geografien „Germany“ und „West Europe“ interessant. Erstere umfasst z. B. zwei Regionen „Germany West Central“ (Frankfurt) und „Germany North“ (Berlin).
Jede Azure-Region ist dann innerhalb ihrer Geografie mit genau einer Region gekoppelt, was die direkte Replikation von Ressourcen wie VM-Speicher innerhalb eines Gebiets erlaubt, ohne Compliance-Richtlinien zu verletzten. Das Konzept verringert die Wahrscheinlichkeit, dass Naturkatastrophen, politische Unruhen, Stromausfälle oder physische Netzwerkausfälle durch den Ausfall einer kompletten Region zu Datenverlusten führen. Das Replizieren von Daten für die jeweils unterstützten und vom Kunden explizit so konfigurierten Dienste (z. B. Azure Storage) ist der einzige Fall, bei dem Microsoft mehr oder weniger automatisch Daten eines andern Datacenters kopiert. Da die jeweils gültigen https://learn.microsoft.com/de-de/azure/reliability/cross-region-replication-azure#azure-cross-region-replication-pairings-for-all-geographies Regionskoppelpaare fest definiert sind und nicht vom Kunden bestimmt werden, verletzt dieses Verfahren innerhalb der jeweiligen Geografie niemals etwaige Compliance-Richtlinien. Die Koppelpaare befinden sich je nach geografischen und politischen Gegebenheiten in einem Umkreis von 300 Meilen und verwenden für den Replikationsdatenverkehr den Microsoft-Backbone.
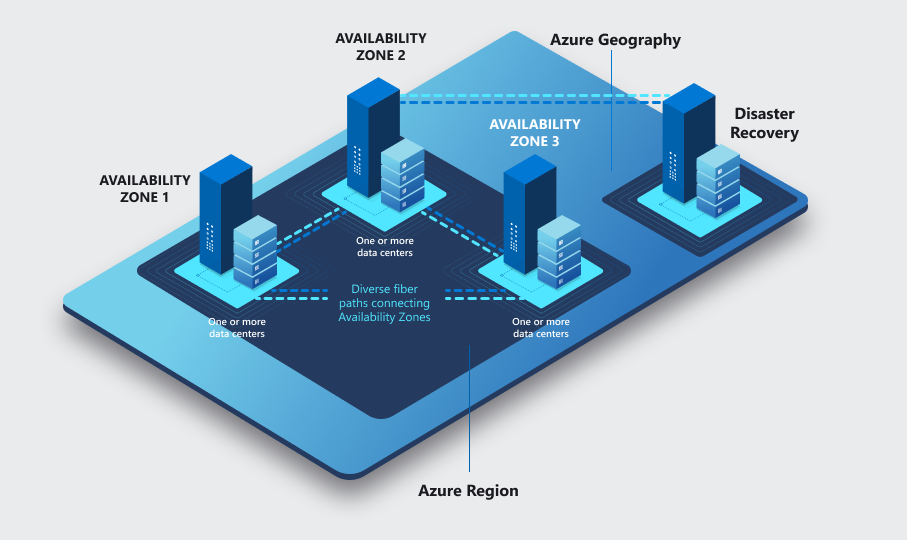
Einige (aber nicht alle) Azure-Regionen bieten dem Kunden die Möglichkeit Ressourcen, statt nur in der jeweiligen Region, explizit in so genannten Verfügbarkeitszone (AZ) zu platzieren. Hierbei handelt es sich um physisch isolierte „Standorte“ innerhalb einer Azure-Region, die jeweils aus mindestens einem Datacenter bestehen und deren Stromversorgung, Kühlung und Netzwerkbetrieb ebenfalls unabhängig funktionieren. Zur Unterstützung von Resilienz gibt es in allen Regionen, die Verfügbarkeitszonen unterstützen, mindestens drei oder mehr Verfügbarkeitszonen.
Diese sind ihrerseits über ein Hochleistungsglasfasernetzwerk mit einer Roundtrip-Latenz von weniger als 2ms verbunden und tragen dazu bei, dass Kunden unternehmenskritische Anwendungsarchitekturen hochverfügbar betreiben können. Nebenstehenden Bild verdeutlicht den Zusammenhang:
Sicherheit und Azure: Die Sicherheit am physischen Standort
Möchtest du im Detail wissen, wie es in einem Microsoft-Rechenzentrum zugeht, kannst du dort nicht einfach ohne eine triftige geschäftliche Begründung hingehen, weil Microsoft den physischen Zugriff auf die Bereiche, in denen deine Daten gespeichert werden streng kontrolliert. Du kannst aber jederzeit einen https://news.microsoft.com/stories/microsoft-datacenter-tour/ virtuellen Rundgang starten.

Innerhalb der Stufe „Physische Sicherheit“ verfolgt Microsoft dann wiederrum einen mehrstufigen Ansatz, der verhindert, dass nicht autorisierte Benutzer physischen Zugriff auf Daten und Rechenzentrumsressourcen erlangen könnten. So besitzen sämtliche von Microsoft verwaltete Rechenzentren mehrere Schutzebenen, die z. B. Zugriffsgenehmigung an der Einrichtungsgrenze, an der Gebäudegrenze, im Gebäude und in der Rechenzentrumsetage umfassen. Angenommen, es gäbe eine triftige geschäftliche Begründung für einen Besuch, würde dieser etwa folgendermaßen ablaufen:
Sicherheit und Azure: Physischer Zugang zum Rechenzentrum
Zunächst muss jeder potenzielle Besucher einen Zugang anfordern, „bevor“ er am Rechenzentrum eintrifft. Solche Anforderungen werden nach Notwendigkeit des Zugangs von Microsoft-Mitarbeitern genehmigt, wodurch sich laut Microsoft die Anzahl der Microsoft-Mitarbeiter, die für die tatsächliche Durchführung einer Aufgabe in Rechenzentren erforderlich sind, auf ein absolutes Minimum verringern lässt. Sollte Microsoft einem Besucher eine Berechtigung erteilen, erhält dieser ausschließlich zu genau dem abgegrenzten Bereich des Rechenzentrums Zugang, der der genehmigten geschäftlichen Begründung entsprechend notwendig ist.
Solche Berechtigungen sind auf einen engen Zeitraum befristet und laufen danach ab. Dabei werden sämtliche Badges für temporäre Zugänge im einem zugangsgesteuerten SOC (Service Organization Control) gespeichert und zu Beginn und Ende jeder Schicht inventarisiert, sodass jeder Besucher mit genehmigtem Zugang zum Rechenzentrum ein solches Badge mit dem Hinweis „Nur in Begleitung und dürfen sich nicht von den Begleitpersonen entfernen“ tragen muss.
Da den begleiteten Besuchern selbst keinerlei Zugriffsebenen gewährt werden, sind diese vom Zugang ihrer Begleiter abhängig und die Begleitperson von Microsoft ist für sämtliche Handlungen und den Zugang des Besuchers während seines Besuchs im Rechenzentrum verantwortlich. Bei Eintreffen an der Einrichtung kann der Besucher diese nur durch einen exakt definierten Zugangspunkt betreten, weil jeder „Millimeter“ aus hohen Zäunen aus Stahl, Beton und einem dichten Netz von Kameras umgeben ist. Zusätzlich sorgt eine patrouillierendes Sicherheitspersonal dafür, dass Besucher nur bestimmte Bereiche betreten können und diese auch wieder verlassen. Zudem schützen Poller und andere Sperranlagen vor etwaigen physischen Bedrohungen von außen. Innerhalb der „Einrichtung“ gelangt der Besucher eskortiert durch seinen Begleiter an den Eingang des Rechenzentrums, der ebenfalls vom Sicherheitspersonal überwacht wird. Dieses geht außerdem routinemäßig das Rechenzentrum ab und überwacht jederzeit die Aufnahmen der Kameras „im“ Rechenzentrum. Für den Zutritt zum Gebäude muss der Nutzer eine zweistufige Authentifizierung mittels biometrischer Daten durchlaufen, um sich weiter im Rechenzentrum bewegen zu können. Wie oben beschrieben nur für den Bereich, für den der Zugang genehmigt wurde. Das gilt auch für die spezifische Etage.
Auch hier durchläuft der Besucher wieder eine Personenkontrolle mit Metalldetektor. Damit nicht ohne Wissen von Microsoft unberechtigte Daten in das Rechenzentrum gelangen oder dieses verlassen, dürfen Besucher nur genehmigte Geräte in die Rechenzentrumsetage mitnehmen. Hier überwachen Kameras die Vorder- und Rückseite jedes Server-Racks. Beim Verlassen der Rechenzentrumsetage durchläuft der Besucher erneut eine vollständige Personenkontrolle mit Metalldetektor sowie weitere Sicherheitsüberprüfungen.
Sicherheit und Azure: Wie sehen die physischen Server-Knoten aus?
Das Wesen der Public-Cloud besteht darin, dass Benutzer über das Internet per HTTP-Anfragen (REST-API) IT-Ressourcen bereitstellen können, die je nach Abstraktionsebene (PaaS, IaaS) letztendlich auf von Microsoft betriebenen virtuellen Maschinen „aufgelöst“ werden. Diese VMs werden bei Azure grundsätzlich auf einem „Azure“-Hypervisor ausgeführt. Dieser ist technologisch betrachtet ähnlich – aber nicht gleich – einem Hyper-V und grundsätzlich zur Verwendung in der Cloud konzipiert und damit generell öffentlich zugänglich. Dieser Hypervisor teilt jeden „Knoten“ (physischen Host) in eine variable Anzahl von Kunden-VMs auf. Das Paravirtualisierungs-Prinzip von Hyper-V sorgt außerdem dafür, dass jeder Knoten über eine „Parent/Root“-Partition (Microsoft spricht von Stamm-VM) verfügt, auf der das Host-Betriebssystem mit aktivierter Windows-Firewall läuft, wobei in einer Service-Definitionsdatei die adressierbaren Ports definiert sind.
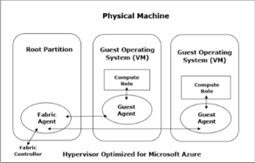
Nur diese sind intern wie extern adressierbar, wobei der gesamte Datenverkehr und der Zugriff auf Datenträger und Netzwerk über den Hypervisor und das Root-OS „vermittelt“ werden. Das auf der Host-Ebene ausgeführte Betriebssystem ist ein angepasstes Windows-Server-OS mit „Azure“-Hypervisor, welches nur aus den zum Hosten von VMs essentiell erforderlichen Komponenten besteht, was wiederrum die Leistung optimiert und die Angriffsfläche verkleinert.
VMs, die auf diesen physischen Knoten laufen werden in Clustern von je 1000 VMs gruppiert und unabhängig von einer horizontal skalierten und redundanten Plattform-Komponenten mit der Bezeichnung Fabric Controller (FC) verwaltet. Dabei ist jeder FC für das Verwalten der Lebenszyklen von Anwendungen, die in seinem Cluster ausgeführt werden, verantwortlich. Der FC kontrolliert die Bereitstellung und Überwachung der Integrität der Hardware, führt selbständig Vorgänge aus, wie etwa das erneute Aktivieren von VM-Instanzen auf fehlerfreien Servern – sollte ein Server ausfallen – und kümmert sich um sämtliche Anwendungsverwaltungsvorgänge wie das Bereitstellen, Aktualisieren und das horizontale Skalieren von Anwendungen.
Die untenstehende Abbildung verdeutlicht den Zusammenhang, einschließlich der Verknüpfung zum jeweiligen Storage-Knoten. Bekanntlich ist immer ein Teil der Host-Flotte in jedem Microsoft-Rechenzentrum für den Betrieb der Speichervirtualisierungsschicht zuständig. Diese stellt unter anderem den Dienst Azure Storage bereit, welcher die jeweiligen OS- und Daten-Datenträger der Kunden-VMs als Objektspeicher-Objekte (Azure Blobs) aufnimmt (Managed Discs). Aus Sicht der VMs handelt es sich um Blockgeräte, die über das Netzwerk an die VMs angeschlossen sind, vergleichbar mit on premise aus einem SAN bereitgestellten LUNs, die über das lokale Netzwerk dem jeweiligen Server als Block-Devices präsentiert werden. Da weder OS- noch Daten-Datenträger vom jeweiligen Compute-Node der VM bereitgestellt werden, kann der FC VMs, die aufgrund eines Host-Fehlers ausfallen jederzeit neu starten und die Datenträger wieder anhängen:
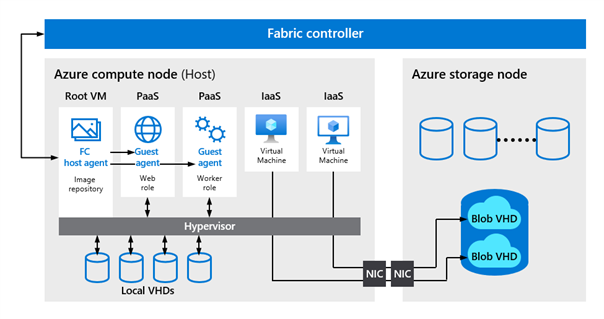
Da nun das gesamte Rechenzentrum in Cluster unterteilt ist, werden Fehler auf FC-Ebene isoliert, was wiederrum verhindert, dass bestimmte Fehlerklassen über den Cluster in dem sie passieren hinaus Auswirkungen auf anderen Server haben, d. h. Fabric Controller, die einen bestimmten Azure-Cluster bedienen, werden immer in einem FC-Cluster gruppiert.
Betriebssystem-Images
Bei Microsoft gibt es spezielle Teams, die sich ausschließlich darum kümmern, Machine Images in Form von virtuellen Festplatten sowohl für Hosts als auch für Gast-VM bereitzustellen und zu pflegen. Diese Basis-Images werden mit Hilfe eines automatisierten Offline-Build-Prozesses erstellt, wobei es sich bei jedem Basis-Image um je eine spezielle Betriebssystem-Version handelt, bei der Kernel und andere Kernkomponenten zur Unterstützung von Azure geändert und optimiert sind. Generell wird bei den OS-Images unterschieden zwischen denen, die für Host-VMs bestimmt sind (Host), denen, die für Gast-VMs bestimmt sind (Gast) und solchen, die ein natives Betriebssystem auf Mandanten-Ebene bereitstellen (Nativ), etwa für Azure Storage. Dabei verwenden die Images der Host- und Native-Ebene verstärkte Sicherheit, da sie die Fabric-Agenten hosten und die jeweilige Parent-VM auf einem Compute- oder Speicherknoten ausführen. Dies verringert massiv die Angriffsfläche, welche sich bei der Public Cloud zwangsläufig durch APIs oder nicht verwendete Komponenten ergibt. Einige interne Azure-Komponenten werden übrigens auf VMs mit Gast-OS-Image ausgeführt und bieten nicht die Möglichkeit, das RDP-Protokoll auszuführen.
Auch der nächste Teil dieser kleinen Serie befasst sich sicherlich immer noch mit dem Physical Layer. Dann schauen wir explizit auf die Sicherheit der Azure-Hardware und die Firmware einschließlich der Codeintegrität, UEFI-Secure-Boot, TPM für den gemessen Start, Verschlüsselung ruhender Daten und die Sicherheit des Azure-Hypervisors im Allgemeinen.
Kontakt

„*“ zeigt erforderliche Felder an

