Was ist Azure OpenAI?

Der Azure-Dienst „Azure OpenAI“ ist das Ergebnis der Partnerschaft von Microsoft mit OpenAI. Er kombiniert die Funktionen für generative KI-Modelle von OpenAI mit Azure-Enterprise-Funktionen. So können Unternehmen die KI-Modelle von OpenAI – darunter ChatGPT – in einem gesicherten Unternehmenskontext testen und nutzen. Das bietet dir neben einer komfortableren Test-Umgebung mit dem Azure-AI-Studio die Sicherheit, das Open AI die von dir getätigten Eingaben z. B. nicht weiter nutzt, etwa zum Trainieren seiner Modelle.
Passende Schulungen
AI-900 – Microsoft Azure AI Fundamentals (AI-900T00)
AI-900 – Microsoft Azure AI Fundamentals (AI-900T00): Einführung in künstliche Intelligenz (AI) und Grundlagen von AI in Azure

AI-102 – Designing and Implementing a Microsoft Azure AI Solution (AI-102T00)
Weitere Informationen und praktische Übungen bekommst du in unseren Microsoft Azure Schulungen!
Azure OpenAI: Mehr als Chat-GPT
Azure OpenAI ist aus einer Zusammenarbeit von Microsoft mit dem Unternehmen OpenAI, unter anderem bekannt für Chat-GPT – entstanden. Bekanntestes Ergebnis der Zusammenarbeit ist die Integration von Chat-GPT 4 in Microsofts Suchmaschine Bing. Im Rahmen von „Bing Chat Enterprise“, das für alle Organisation, die über einen entsprechend berechtigten M365-Plan (Business Standard, Business Premium, E3 oder E5) verfügen, seit Ende August 2023 in den Einstellungen des Mandanten standardmäßig aktiviert ist, bindet Edge for Business die Suchmaschine direkt in die Seitenleiste ein:
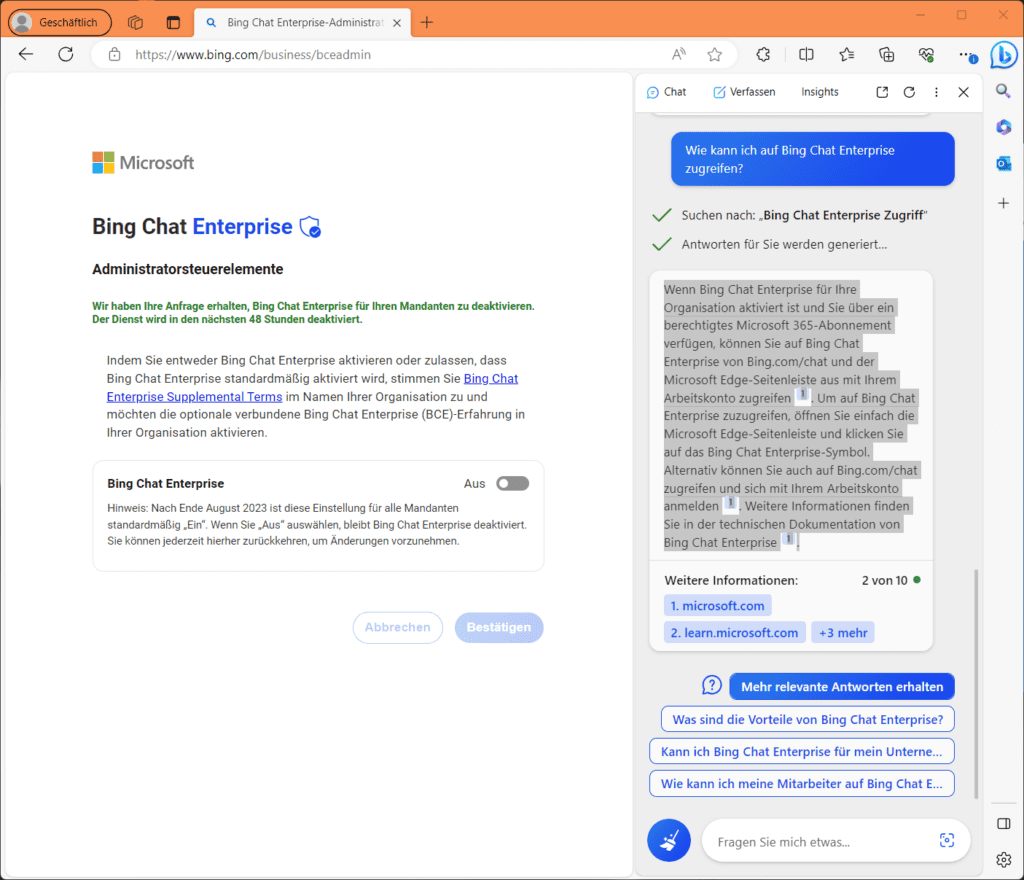
Alternativ erreichst du Bing Chat Enterprise unter bing.com/chat und kannst dich dann als M365-Abonnent mit deinen Arbeitskonto anmelden. Allgemein stellt OpenAI seine KI-Modelle Entwicklern für das Erstellen neuen Softwareanwendungen zur Verfügung. Dazu gibt es neben Chat-GPT noch viele andere interessante Beispiele auf der https://platform.openai.com/examples OpenAI-Website.
Kategorisieren lassen sich die heute verfügbaren KI-Modelle grob nach KI-Modellen zum Imitieren menschlichen Verhaltens, ML-Algorithmen zum adaptiven Anpassen vorhandener Modelle an Daten, um Vorhersagen zu treffen, Deep-Learning-Modellen, die Algorithmen in Form neuronaler Netze nutzen und generativen KI-Modellen. Letztere sind in der Lage, neue Inhalte auf Basis der eingegebenen Beschreibungen zu generieren. Bei den KI-Modellen von OpenAI handelt es sich um Sammlungen verschiedener generativer KI-Modellen, welche Sprache, Bilder oder Code generieren können.
Azure OpenAI – die Ziele
Mit der Zusammenarbeit mit OpenAI verfolgt Microsoft nach eigener Angabe mehrere Ziele. In erste Linie geht es um die Nutzung der Azure-Infrastruktur beim Erstellen von Anwendungen auf Enterprise-Niveau mit allem was dazu gehört, also dem gesamten Stack aus Sicherheit, Compliance und regionaler Verfügbarkeit.
Passende Schulungen
ChatGPT
ChatGPT - Die unverzichtbare Künstliche Intelligenz

Ferner geht es Microsoft auch um das Zurverfügungstellen von OpenAI-KI-Modellfunktionen für alle Microsoft-Produkte, nicht nur für die Azure KI-Produkte. Denke da z. B. an die verschiedenen geplanten oder schon veröffentlichten CoPilot-Produkte. Andersherum geht es aber auch darum, Azure zur Unterstützung sämtlicher Workloads von OpenAI nutzen zu können. Der Dienst Azure OpenAI steht ausschließlich Azure-Nutzern zur Verfügung und umfasst derzeit vier Komponenten.
- Vortrainierte generative KI-Modelle
- Anpassungsfunktionen, die es ermöglichen, die KI-Modelle mit eigenen Daten zu optimieren
- Werkzeuge zum Erkennen und Entschärfen schädlicher Anwendungsfälle
- Sicherheit-Ebene mit rollenbasierter Zugriffssteuerung (RBAC) und privaten Netzwerken
Dank Azure OpenAI kannst du im Verlauf deiner täglichen Arbeit nahtlos zwischen Azure-Diensten im Azure-Portal und dem und https://oai.azure.com/portal OpenAI-Portal wechseln und hast in letzterem trotzdem die Möglichkeit, private Netzwerke, die regionale Verfügbarkeit und die Inhaltsfilterung zu nutzen.
Azure OpenAI unterstützt viele gängige KI-Workload-Typen, wie maschinelles Lernen, maschinelles Sehen, Verarbeitung natürlicher Sprache, Chat-KI, Anomalie-Erkennung und Knowledge-Mining, bietet aber auch Lösungen für Neue. Darüber hinaus unterstützt Azure OpenIA viele weitere KI-Workloads, die du grob in die Kategorien Generieren natürlicher Sprache, Code oder Bilder gruppieren kannst. Ersteres umfasst das sowohl die Textvervollständigung (Generieren und Bearbeiten von Text) als auch Einbettungen wie Suchen, Klassifizieren und Vergleichen von Text. Außerdem kannst du sowohl Code, als auch Bilder generieren und bearbeiten.
Andere Azure KI-Dienste
Vielleicht fragst du dich, in welcher Beziehung Azure OpenIA zu den vielen anderen KI-basierenden Azure-Services steht, wie z. B. „Azure Machine Learning“, „Cognitive Services“, Computer vision“ oder „Speech services“?
Letztlich hängt alles davon ab, was dein Ziel ist, denn leider gibt es sehr viele sich überschneidenden Funktionen z. B. zwischen dem Sprachdiensten der Azure-KI-Services und dem Azure OpenAI Service, etwa im Bereich Übersetzung, Schlüsselwortextraktion oder Stimmungsanalyse. Zudem gibt es auch von Microsoft keine exakten Aussagen dazu, welchen Service du wann einsetzt, aber allgemein kannst du davon ausgehen, dass sich der neue Azure OpenAI-Dienst für Szenarien empfiehlt, die hochgradig angepasste generative Modelle erfordern.
Arbeiten mit Azure OpenAI
Zum gegenwärtigen Zeitpunkt musst du den Zugriff auf Azure OpenAI erst einmal für eine Azure-Subscription deiner Wahl und einem entsprechenden Konto aus deinem EntraID-Mandanten unter der URL https://aka.ms/oaiapply beantragen. Dabei musst du eine Umfrage ausfüllen, was etwas Zeit in Anspruch nimmt.
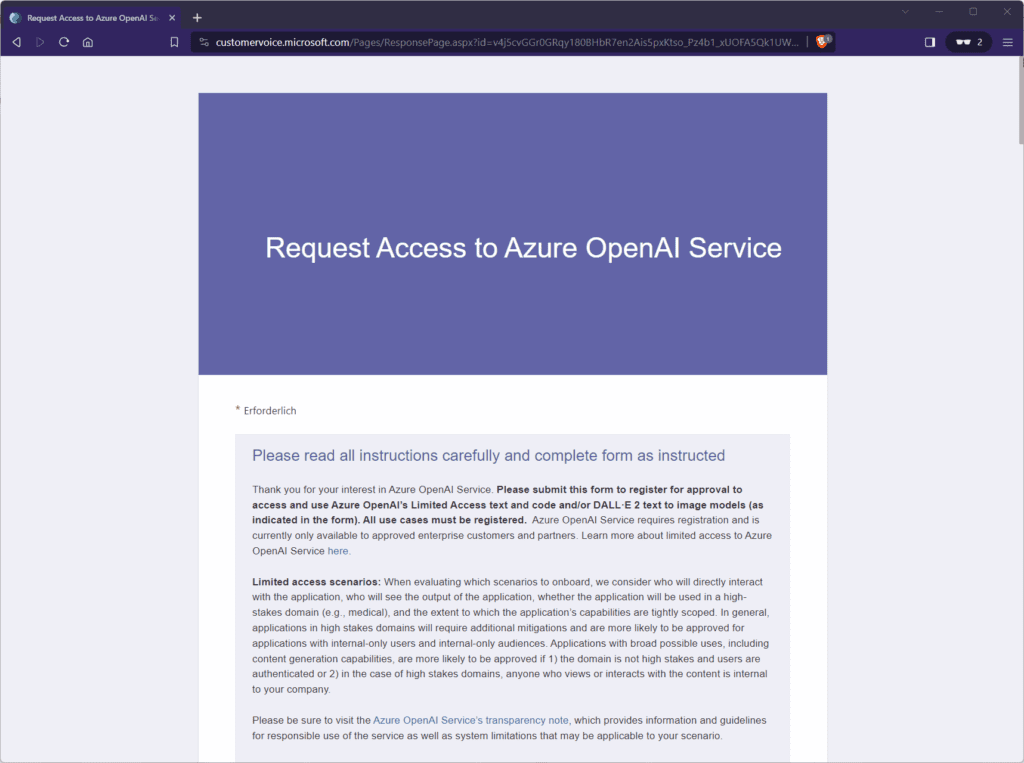
Die meisten Fragen zielen darauf ab, welche Dienste du nutzen möchtest und was generell deine Ziele sind. Außerdem benötigt Microsoft deine Firmendaten und Angabe zur Company-Website, dein „Gewerbe“ (ISV, MSP, MVP usw.) sowie natürlich deine Adress- und Kontaktdaten. Die Überprüfung der Eingaben kann laut Microsoft bis zu 10 Tage dauern, war aber z. B. in meinem Fall in nicht einmal 12 Stunden erledigt und genehmigt.
Sobald der Zugriff von Microsoft genehmigt wurde, kannst du den Dienst nutzen, indem du zunächst eine Azure OpenAI-Ressource erstellst.
Danach kannst du via REST-API, die webbasierte Schnittstelle in Azure OpenAI Studio oder programmatisch über das Python SDK mit dem Dienst arbeiten. Im Falle des Azure-OpenAI-Studios, der Web-Schnittstelle zu Azure-OpenAI klickst du dazu auf „Ressource erstellen“, nachdem du bei „Möchten Sie das Verzeichnis wechseln“ den richtigen Entra-ID-Mandanten ausgewählt hast.
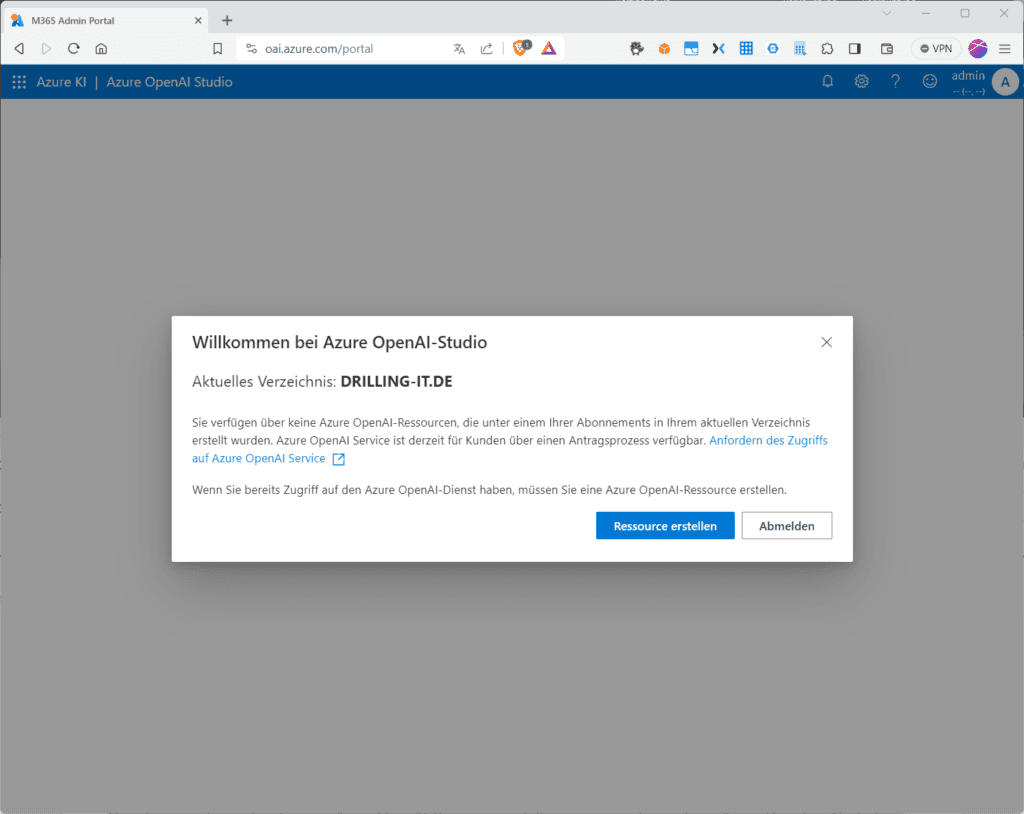
Du musst dann im Dialog „Azure Open AI erstellen“ wie üblich ein Azure-Abonnement, eine Region sowie eine Ressourcen-Gruppe auswählen, dann einen Namen vergeben und ein „Pricing tier“ bestimmen.
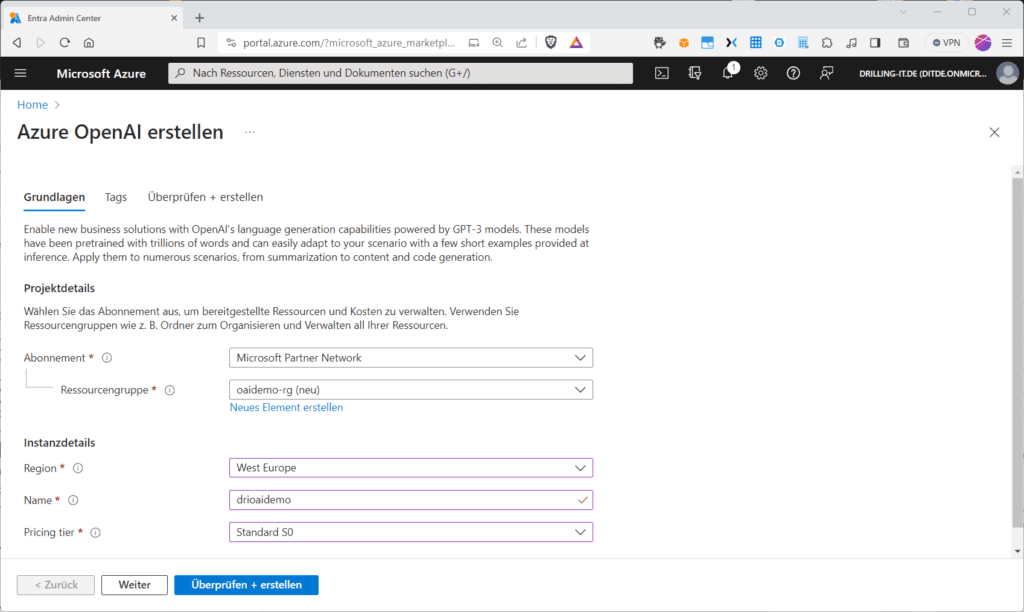
Nach der erfolgreichen Bereitstellung deines Azure-OpenAI landest du zuerst auf der Übersichtsseite.
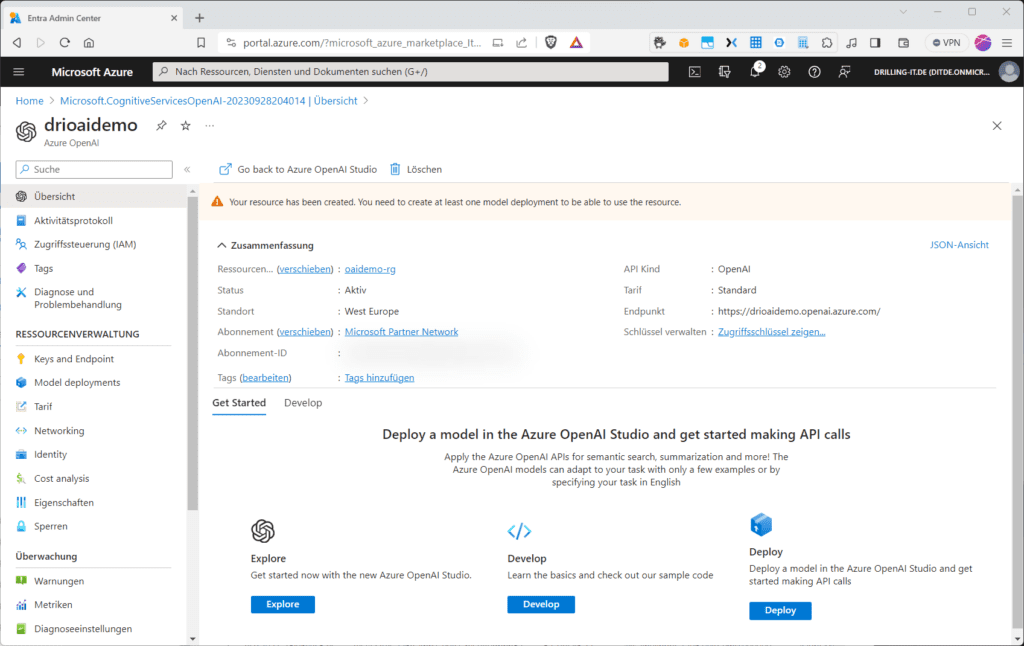
Hier könntest du wie bei allen Azure-Ressourcen Meta-Daten sehen oder überprüfen. Im „Get Started“-Tab kannst du entweder ein neues Model ins neue „Azure OpenAI Studio“ bereitstellen oder dich generell mit dem Azure OpenAI-Studio, sowie auf Basis von Beispiel-Code mit Basis-Wissen für Entwickler vertraut machen. Klickst du auf „Explore“ oder „Deploy“ landest du im Azure OpenAI Studio auf der Seite „Verwaltung /Bereitstellungen“. Auf der kannst du z. B. ein Basismodell bereitstellen. Außerdem kannst du im Hauptmenü erkennen, dass es dort den Abschnitt „Playground“ gibt, in welchem du direkt mit der Bereitstellung von Modellen für „Chat“ (GPT 4 und 3.5), „Einbettungsmodellen“ oder „DALL-E“ starten kannst. „GP“ steht übrigens für „Generative Pre-Trained.
Bei GPT-4-Modellen handelt es sich um die neuste Generation von GPT-Modellen, welche natürliche Sprache und Code-Vervollständigungen auf Basis der Eingabeaufforderungen in natürlicher Sprache generieren. Allerdings steht der Zugriff auf GPT-4-Modelle nur eingeschränkt solchen Kunden zur Verfügung, die sich über dieses https://aka.ms/oai/get-gpt4 Formular explizit darum bewerben. Für den Anfang muss du dich also mit GPT 3.5-Modelle zufriedengeben, wobei insbesondere „GPT-35-turbo“-Modelle speziell für Chat-basierende Interaktionen optimiert sind und daher in vielen generativen KI-Szenarien sehr gut funktionieren.
Die zweite Modell-Kategorie „Einbettungsmodelle“ (eigentlich „Completions“, aber die deutsche Übersetzung „Abschlüsse“ in der Abbildung ist mehr als unglücklich) ist in der Lage, Text in numerische Vektoren zu konvertieren. Das ist insbesondere in Szenarien zur Sprachanalyse hilfreich, wie z. B. das Untersuchen von Textquellen im Hinblick auf Ähnlichkeiten).
Die dritte Kategorie „DALL-E-Modelle“ dient dem KI-gestützten Generieren von Bildern auf Basis einer Eingabeaufforderungen in natürlicher Sprache. DALL-E-Modelle sind derzeit noch Previews. Der Begriff DALL-E steht übrigens für eine Satz von von OpenAI entwickelten KI-Anwendungen, die Bilder aus Textbeschreibungen mithilfe von maschinellem Lernen erstellen können. Der Name lehnt sich an die Figur des leinen animierten Roboters „Wall-E“ aus dem gleichnamigen Film an, der wiederrum auf den spanischen Surrealisten Salvador Dalí zurück geht (Quelle: Wikipedia). DALL-E ist zudem nur in der Region East US verfügbar. Der Unterschied zwischen den einzelnen Modellen liegt in der Performance, den Kosten und darin, dass sie sich für bestimmte Aufgaben mehr oder weniger gut eignen. Details findest du in der https://learn.microsoft.com/de-de/azure/cognitive-services/openai/concepts/models Dokumentation von OpenAI.
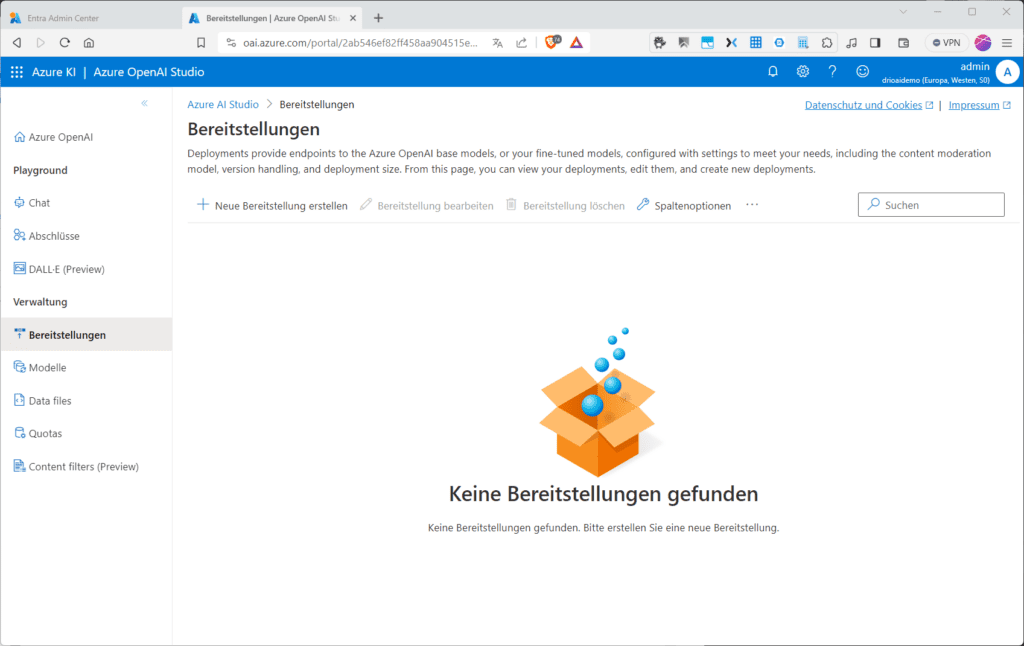
Bereitstellungen
Du startest das Zurverfügungstellen einer neuen Bereitstellung „Deployment“ auf Basis eines der mitgelieferten oder eines deiner eigenen Modelle, z. B. für Vervollständigungen (Completions), indem du unter „Verwaltung / Bereitstellungen“ auf „Neue Bereitstellung erstellen“ klickst.
Erst wenn du ein Modell bereitgestellt hast, kannst du Vervollständigungen von Eingabeaufforderungen erhalten oder (REST)-API-Aufrufe absetzen. Du musst dann im Dialog „Modell bereitstellen“ ein Modell wählen. Zur Verfügung stehen „gpt-35-turbo“, „text-embedding-ada-002“ und „whisper“).
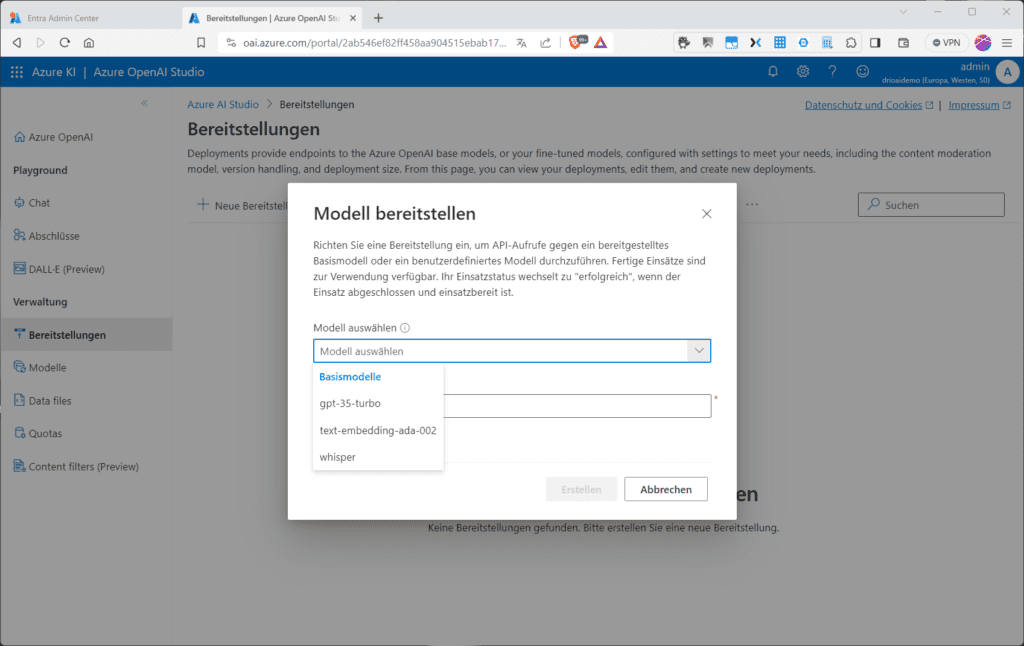
Du kannst ein Modell aber alternativ auch über das Powershell-Commandlet https://learn.microsoft.com/en-us/cli/azure/cognitiveservices/account/deployment?view=azure-cli-latest „az cognitiveservices account deployment create“ oder durch einen REST-API-Call bereitstellen.
Du könntest ein Modell verwenden, das Eingabeaufforderungen vervollständigt. Dabei lassen sich verschiedene Eingabeaufforderungstypen unterscheiden wie z. B. „Führen einer Unterhaltung“, Generieren neuer Inhalte“, „Klassifizieren von Inhalten“, „Transformation“ usw.. Der Qualität der erzielbaren Vervollständigungen richtet sich dann z. B. danach, wie die Eingabeaufforderung aussieht (Details dazu findest du unter dem Stichwort „Prompt Engineering“), den verwendeten Modell-Parametern und natürlich nach den Daten, anhand derer das Modell trainiert wurde. Das bedeutet aber im Umkehrschluss auch, dass du viel mehr Kontrolle über die erzielbaren Vervollständigungen hast, wenn du vorher ein benutzerdefiniertes Modell trainiert hast, als durch einfachen Prompt-Engineering, bzw. das Anpassen von „Parametern“. Microsoft empfiehlt übrigens für Vervollständigung dringend das Modell „text-embedding-ada-002 (Version 2)“. Mit dem hast du Feature-Parität zu „text-embedding-ada-002“ von OpenAI. OpenAI beschreibt in einem umfangreichen https://openai.com/blog/new-and-improved-embedding-model Blog-Beitrag die Verbesserungen gegenüber der Version 1.
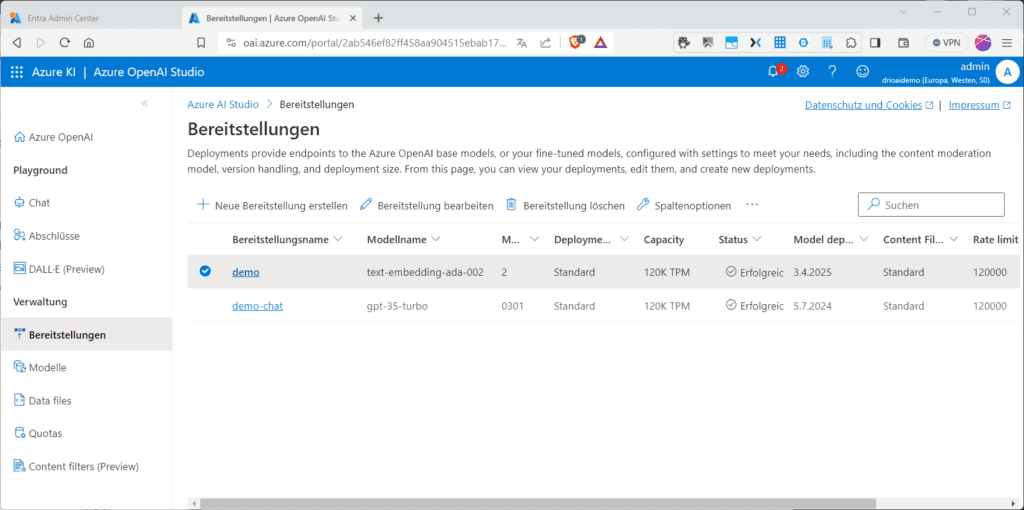
Letztendlich handelt es sich bei „Bereitstellungen“ um Endpunkte für die Azure OpenAI-Basismodelle oder deine eigenen Modelle, die mit Einstellungen konfiguriert sind, welche deinen Anforderungen entsprechen, einschließlich des Inhaltsmoderationsmodells, der Versionsverarbeitung und der Bereitstellungsgröße. Du kannst verschiedenste Bereitstellungen mit unterschiedlichen Modellen haben.
OpenAI Studio Playground
Für erste Experimente mit den verschiedenen Modellen im Azure OpenAI Studio sollest du dir zunächst die Playgrounds ansehen, denn Playgrounds, z. B. für Vervollständigungen (Completitions) stellen dir eine GUI-Oberfläche mit Textein und -ausgabe zur Verfügung, mit deren Hilfe du ganz ohne Code Aufrufe in einem der bereitgestellten Modelle ausführen und die Modell-Parameter anpassen kannst. Wählen dazu im Menü im Abschnitt „Playground“ den Eintrag „Complitions“ (Abschlüsse) und dann im Listenfeld „Bereitstellungen“ das gewünschte Modell. Beachte, dass Playgrounds für „Vervollständigungen“ derzeit nur Chat-Modelle unterstützen, also „gpt-35-turbo“-basierende Modelle. Im Listenfeld „Beispiel“ kannst du dich dann mit den verschiedenen mitgelieferten Beispielen vertraut machen.
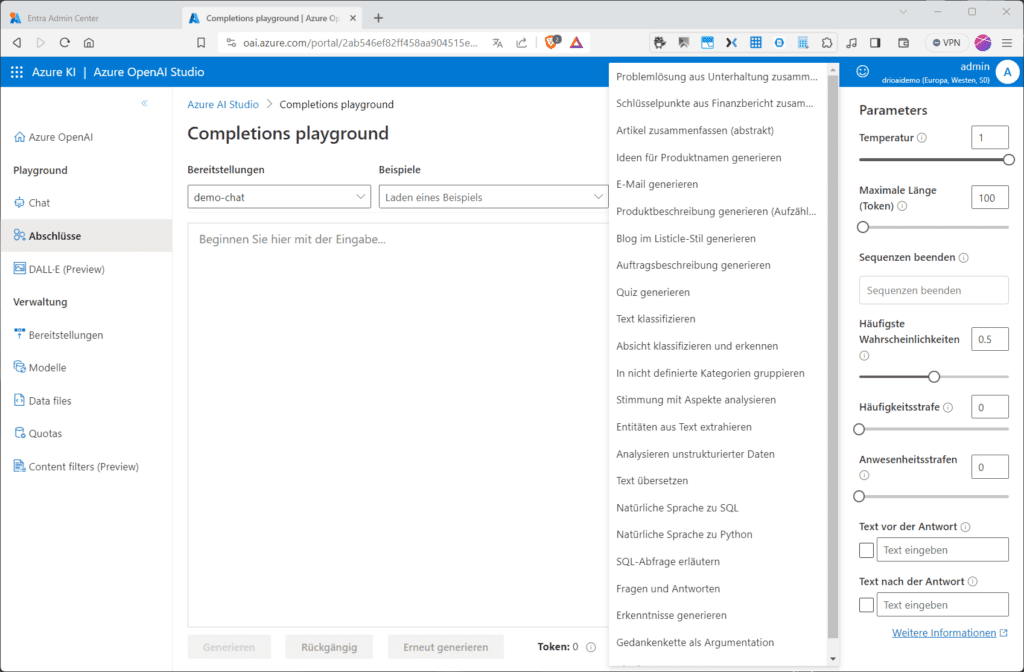
In der Abbildung haben wir „Artikel zusammenfassen (abstrakt)“ aus den mitgelieferten Beispielen gewählt.
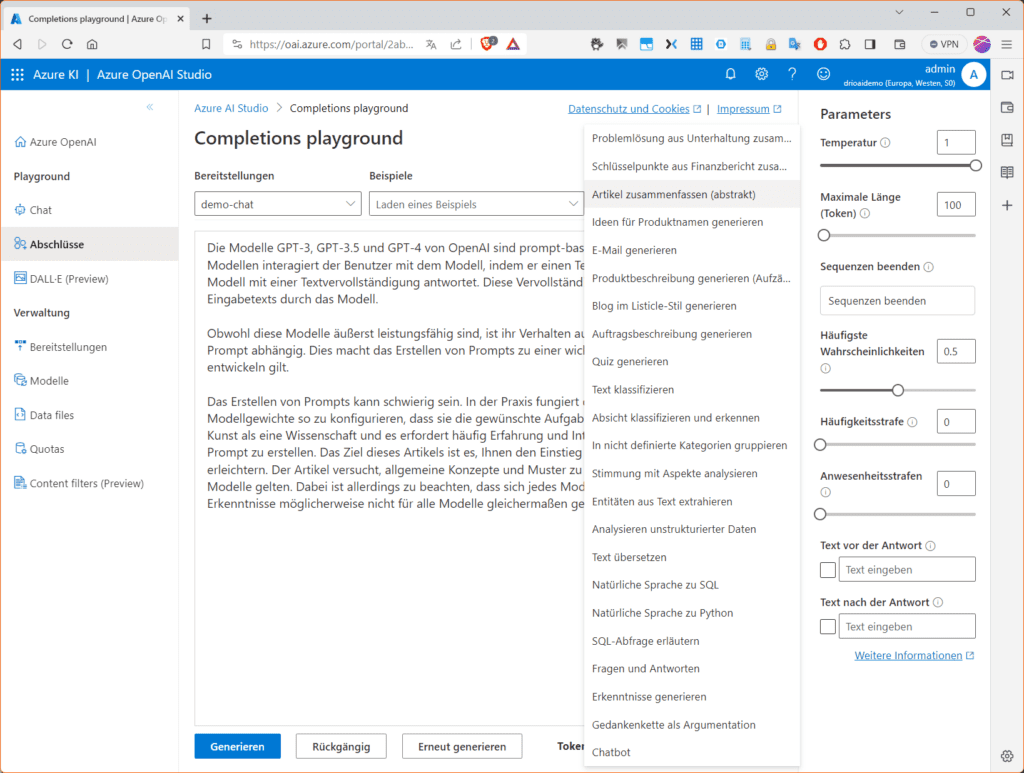
Klickst du dann auf „Generieren“ erstellt das Modell eine Zusammenfassung des Textes unter Berücksichtigung des aktuellen „Trainingsstands“ des Modells und der rechts voreingestellten „Parameter“-Werte.
In der Abbildung findest du das Ergebnis, welches möglicherweise verbesserungswürdig ist, sodass du dich zumindest mit den wichtigsten „Parametern“ auseinanderzusetzen musst. Die Wichtigsten erklären wie dir hier. Im nächsten Teil steigen wir dann tiefer ins Prompt-Engineering ein.
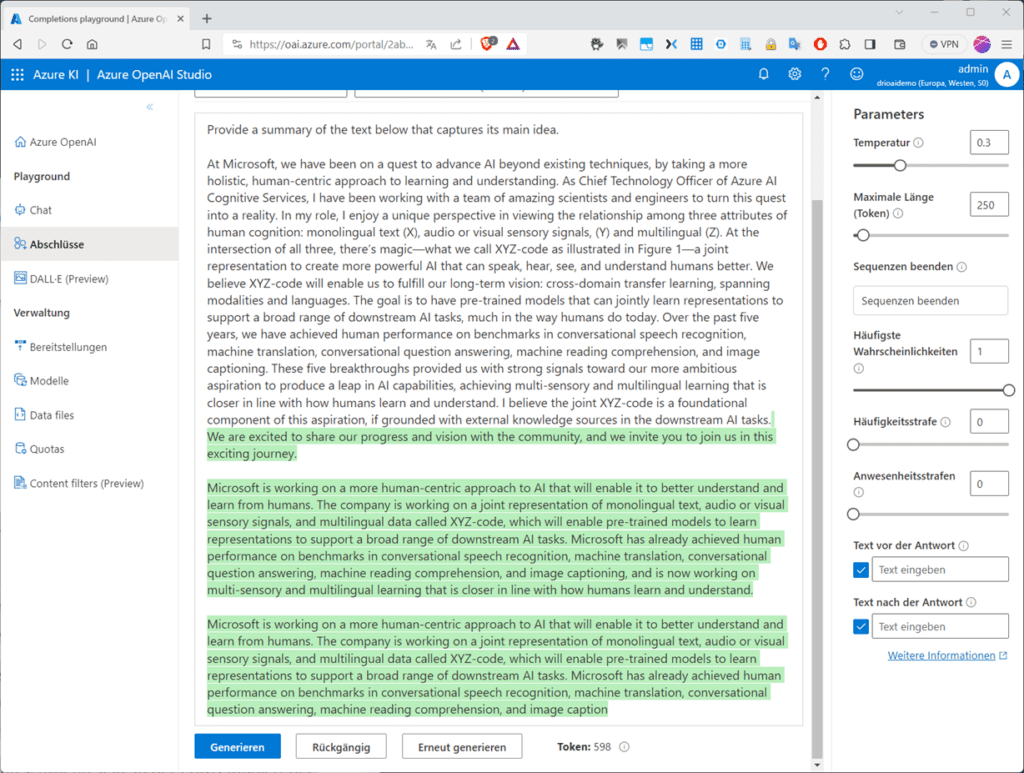
Modell Parameter
- Durch Anpassen der Parameter kannst du die Leistungsfähigkeit des jeweiligen Modells anpassen. Mit dem Parameter „Temperatur“ kannst du die „Zufälligkeit“ steuern. Mit dem Vermindern der Temperatur erzeugt das Modell mehr wiederholte und deterministische Antworten, während ein Erhöhen der Temperatur eher unerwartete, bzw. kreativere Antworten erzeugt. Achte darauf, dass du keinesfalls an den Parametern „Temperatur“ und „Top P“ (s. u) gleichzeitig herumspielst.
- Mit dem Parameter „Maximale Länge (Token)“ kannst du einen Grenzwert für die Anzahl der Token pro Modell-Antwort einstellen. Die API erlaubt maximal 4.000 Token, die zwischen der Eingabeaufforderung (einschließlich Systemmeldung, Beispielen, Nachrichtenverlauf und Benutzerabfrage) und der Antwort des Modells ausgetauscht werden. Bei einem gängigen englischen Text besteht ein Token im Durchschnitt aus etwa vier Zeichen.
- Mit dem Parameter „Sequenzen beenden“ steuerst du, dass die Antworten an einer gewünschten Stelle enden, beispielsweise am Ende eines Satzes oder einer Liste. Du kannst hier bis zu vier Sequenzen angeben, bei denen das Modell das Generieren weiterer Token in einer Antwort beendet.
- Mit „Höchste Wahrscheinlichkeiten (Top P)“ kannst du so ähnlich wie mit dem Parameter „Temperatur“ die Zufälligkeit steuern, allerdings kommt hierbei ein anderes Verfahren zum Einsatz. Ein Absenken von „Top P“ schränkt die Token-Auswahl des Modells auf eher wahrscheinlichere Token ein. Ein Erhöhen von „Top P“ erlaubt dem Modell, aus Token mit hoher und niedriger Wahrscheinlichkeit auswählen.
- Der Parameter „Häufigkeitsstrafe“ verkleinert die Wahrscheinlichkeit, dass ein Token proportional wiederholt wird, in Abhängigkeit davon, wie oft es bislang im Text vorkam. Damit verkleinert sich die Wahrscheinlichkeit, dass der exakt gleiche Text in einer Antwort wiederholt vorkommt.
- Die „Anwesenheitsstrafe“ hingegen verkleinert die Wahrscheinlichkeit, dass ein Token nochmal ausgespielt wird, das bereits im Text vorkam. Damit erhöhst du die Wahrscheinlichkeit, dass das Modell neue Themen in seine Antwort einführt.
- Mit dem Parameter „Text vor der Antwort“ fügst du Text nach der Eingabe des Benutzers und vor der Antwort des Modells ein. Du kannst damit das Modell auf eine Antwort vorbereiten.
- Mit dem Parameter „Text nach der Antwort“ fügst du Text nach der generierten Antwort des Modells ein. Das regt weitere Benutzereingaben an, wenn z. B. eine Unterhaltung modelliert werden soll.
Kontakt

„*“ zeigt erforderliche Felder an

